Affected files: Money/Assets/Financial Instruments.md Money/Assets/Security.md Money/Markets/Markets.md Politcs/Now.md STEM/AI/Neural Networks/CNN/Examples.md STEM/AI/Neural Networks/CNN/FCN/FCN.md STEM/AI/Neural Networks/CNN/FCN/FlowNet.md STEM/AI/Neural Networks/CNN/FCN/Highway Networks.md STEM/AI/Neural Networks/CNN/FCN/ResNet.md STEM/AI/Neural Networks/CNN/FCN/Skip Connections.md STEM/AI/Neural Networks/CNN/FCN/Super-Resolution.md STEM/AI/Neural Networks/CNN/GAN/DC-GAN.md STEM/AI/Neural Networks/CNN/GAN/GAN.md STEM/AI/Neural Networks/CNN/GAN/StackGAN.md STEM/AI/Neural Networks/CNN/Inception Layer.md STEM/AI/Neural Networks/CNN/Interpretation.md STEM/AI/Neural Networks/CNN/Max Pooling.md STEM/AI/Neural Networks/CNN/Normalisation.md STEM/AI/Neural Networks/CNN/UpConv.md STEM/AI/Neural Networks/CV/Layer Structure.md STEM/AI/Neural Networks/MLP/MLP.md STEM/AI/Neural Networks/Neural Networks.md STEM/AI/Neural Networks/RNN/LSTM.md STEM/AI/Neural Networks/RNN/RNN.md STEM/AI/Neural Networks/RNN/VQA.md STEM/AI/Neural Networks/SLP/Least Mean Square.md STEM/AI/Neural Networks/SLP/Perceptron Convergence.md STEM/AI/Neural Networks/SLP/SLP.md STEM/AI/Neural Networks/Transformers/LLM.md STEM/AI/Neural Networks/Transformers/Transformers.md STEM/AI/Properties.md STEM/CS/Language Binding.md STEM/Light.md STEM/Maths/Tensor.md STEM/Quantum/Orbitals.md STEM/Quantum/Schrödinger.md STEM/Quantum/Standard Model.md STEM/Quantum/Wave Function.md Tattoo/Music.md Tattoo/Plans.md Tattoo/Sources.md
577 B
577 B
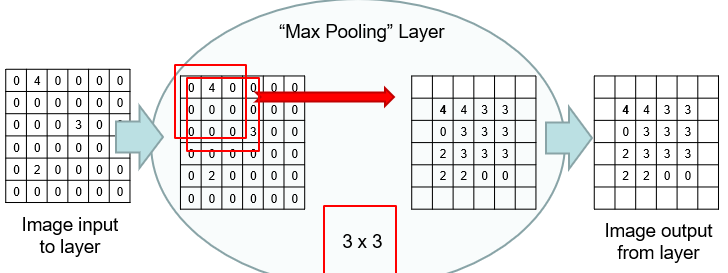
- Maximum within window and writes result to output
- Downsamples image
- More non-linearity
- Doesn't remove important information
- Max value is the good bit
- No parameters
Design Parameters
- Size of input image
- 252 x 252 x 1 x n
- Padding
- Kernel size
- 3 x 3 x 1
- Doesn't need to be odd
- 2 x 2
- Stride
- Typically n
- For n x n kernel size
- Sometimes 4 x 4 in early layers
- 16 times less data
- Rapid downsample
- 16 times less data
- Typically n
- Size of computable output
- 250 x 250 x 1 x n
- Depends on padding and striding
- 250 x 250 x 1 x n