Affected files: STEM/AI/Neural Networks/CNN/Examples.md STEM/AI/Neural Networks/CNN/FCN/FCN.md STEM/AI/Neural Networks/CNN/FCN/ResNet.md STEM/AI/Neural Networks/CNN/FCN/Skip Connections.md STEM/AI/Neural Networks/CNN/GAN/DC-GAN.md STEM/AI/Neural Networks/CNN/GAN/GAN.md STEM/AI/Neural Networks/CNN/Interpretation.md STEM/AI/Neural Networks/CNN/UpConv.md STEM/AI/Neural Networks/Deep Learning.md STEM/AI/Neural Networks/MLP/MLP.md STEM/AI/Neural Networks/Properties+Capabilities.md STEM/AI/Neural Networks/SLP/Least Mean Square.md STEM/AI/Neural Networks/SLP/SLP.md STEM/AI/Neural Networks/Transformers/Transformers.md STEM/AI/Properties.md STEM/CS/Language Binding.md STEM/CS/Languages/dotNet.md STEM/Signal Proc/Image/Image Processing.md
1013 B
1013 B
- Feedforward
- Single hidden layer can learn any function
- Universal approximation theorem
- Each hidden layer can operate as a different feature extraction layer
- Lots of weights to learn
- Back-Propagation is supervised
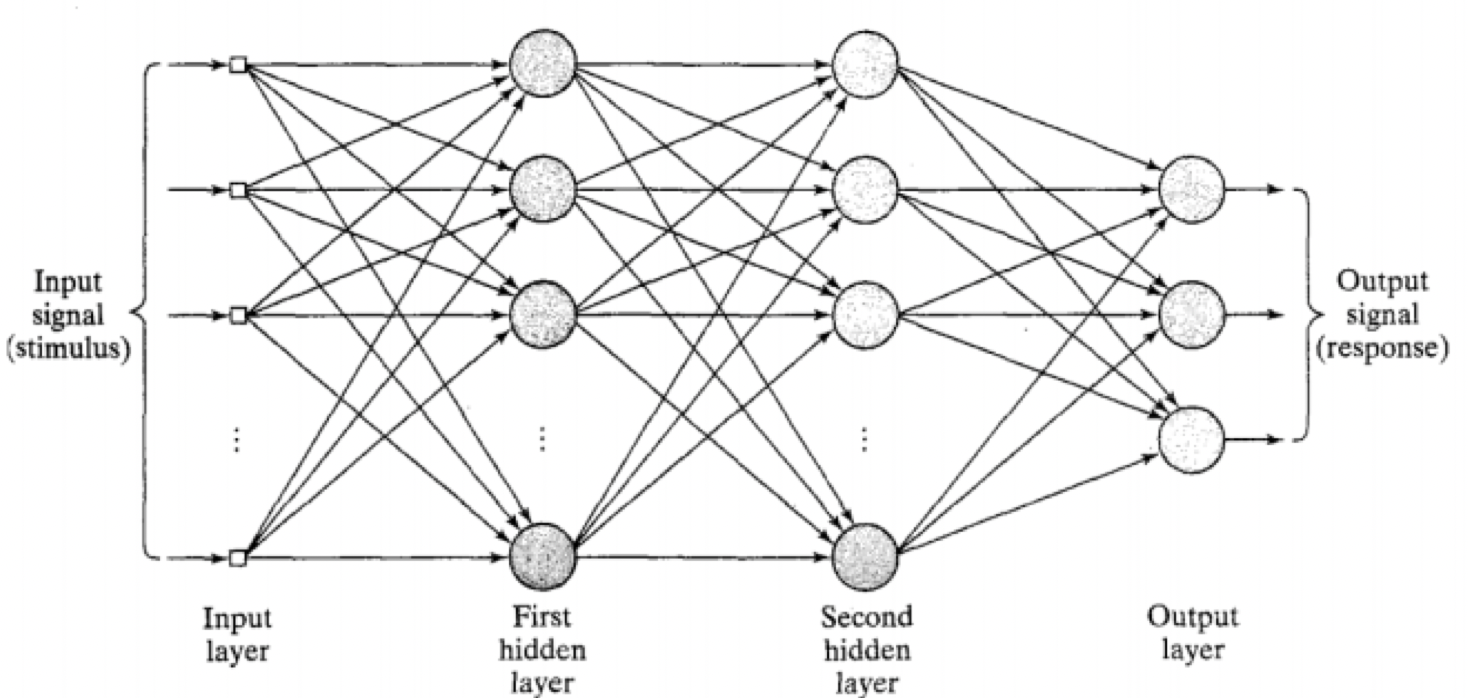
Universal Approximation Theory
A finite feedforward MLP with 1 hidden layer can in theory approximate any mathematical function
- In practice not trainable with BP
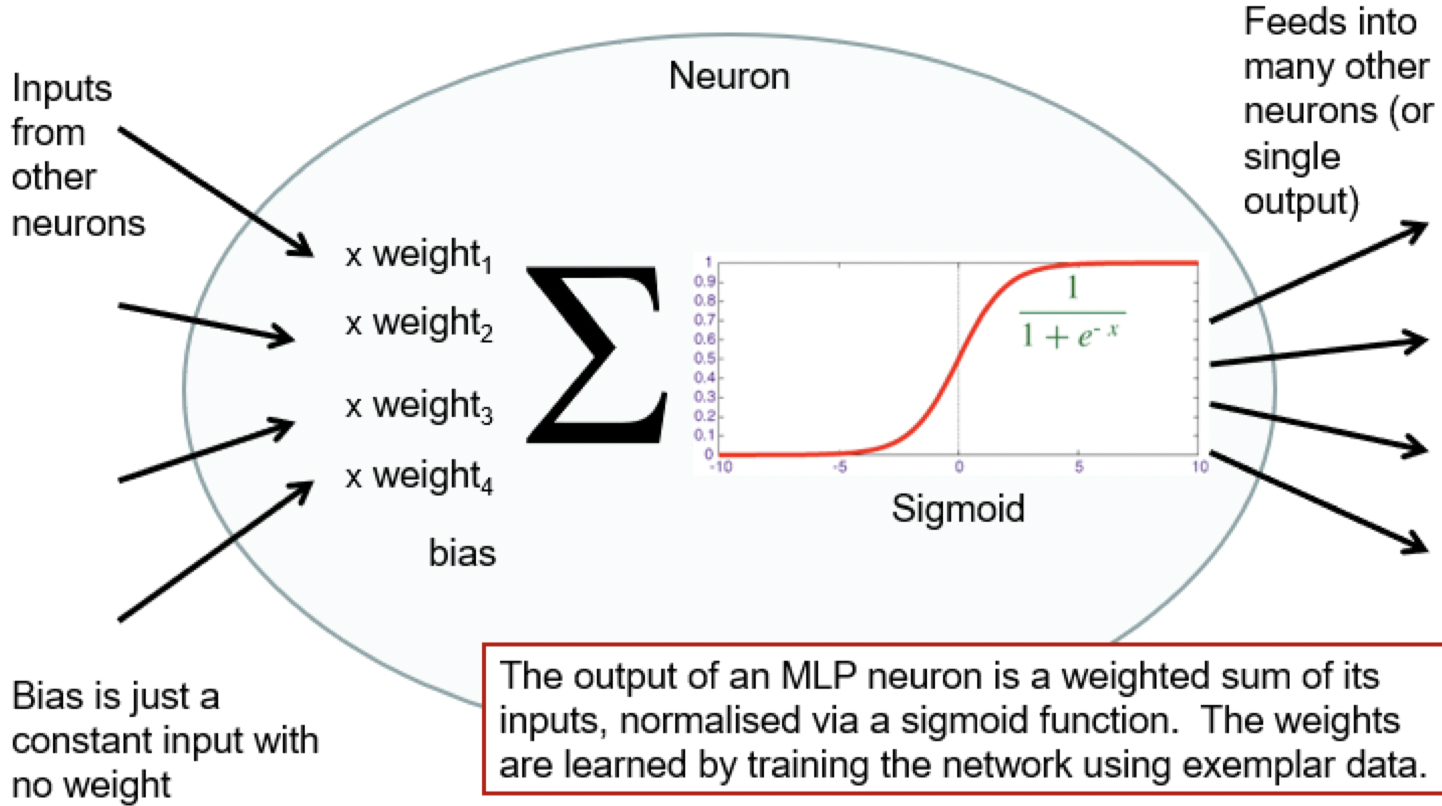
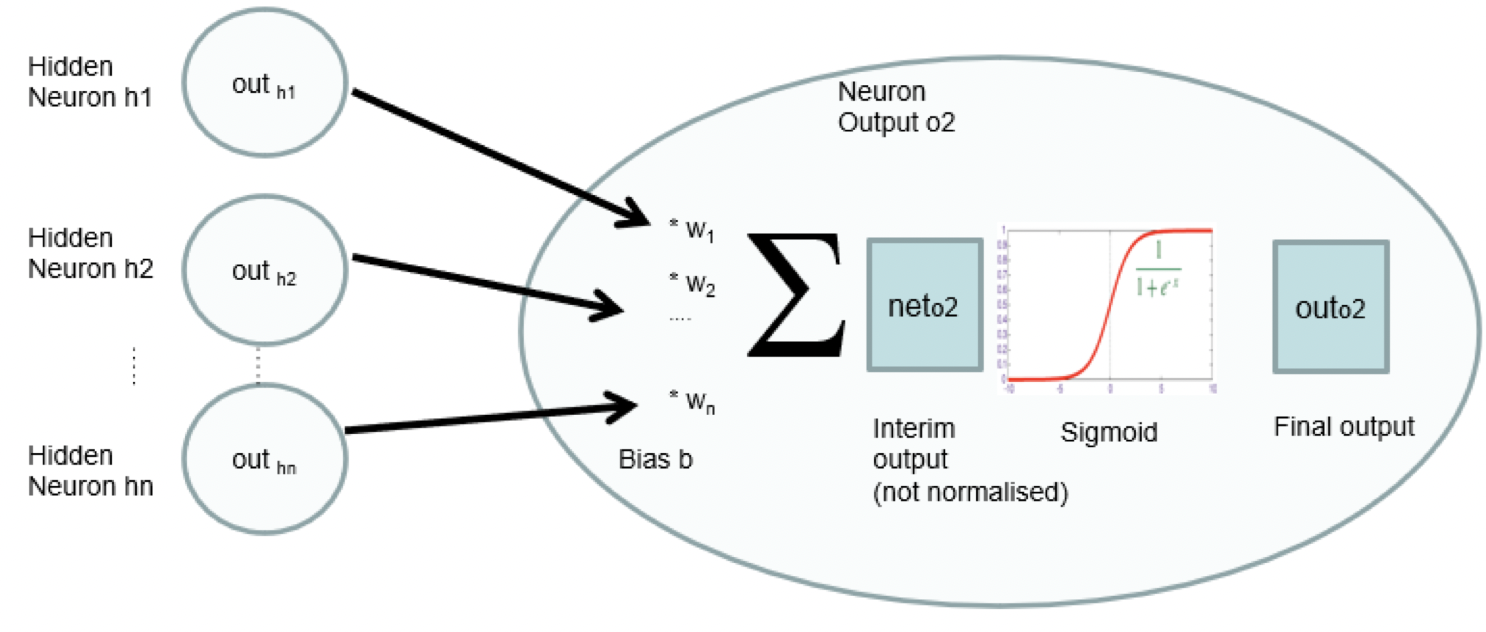
Weight Matrix
- Use matrix multiplication for layer output
- TLU is hard limiter
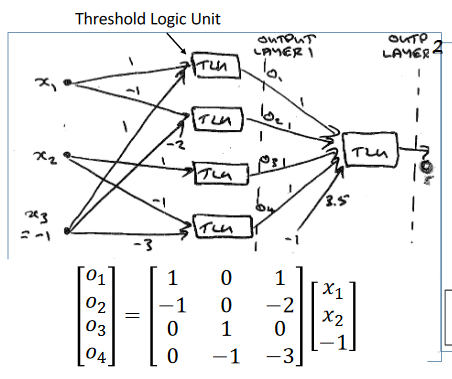
o_1too_4must all be one to overcome -3.5 bias and force output to 1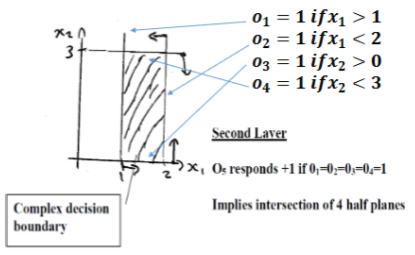
- Can generate a non-linear decision boundary