Affected files: .obsidian/graph.json .obsidian/workspace-mobile.json .obsidian/workspace.json Languages/Spanish/Spanish.md STEM/AI/Classification/Classification.md STEM/AI/Classification/Decision Trees.md STEM/AI/Classification/Logistic Regression.md STEM/AI/Classification/Random Forest.md STEM/AI/Classification/Supervised/SVM.md STEM/AI/Classification/Supervised/Supervised.md STEM/AI/Neural Networks/Activation Functions.md STEM/AI/Neural Networks/CNN/CNN.md STEM/AI/Neural Networks/CNN/GAN/DC-GAN.md STEM/AI/Neural Networks/CNN/GAN/GAN.md STEM/AI/Neural Networks/Deep Learning.md STEM/AI/Neural Networks/Properties+Capabilities.md STEM/AI/Neural Networks/SLP/Perceptron Convergence.md
2.1 KiB
2.1 KiB
| tags | ||
|---|---|---|
|
Error-Correcting Perceptron Learning
- Uses a McCulloch-Pitt neuron
- One with a hard limiter
- Unity increment
- Learning rate of 1
If the $n$-th member of the training set, x(n), is correctly classified by the weight vector w(n) computed at the $n$-th iteration of the algorithm, no correction is made to the weight vector of the perceptron in accordance with the rule:
w(n + 1) = w(n) \text{ if $w^Tx(n) > 0$ and $x(n)$ belongs to class $\mathfrak{c}_1$}w(n + 1) = w(n) \text{ if $w^Tx(n) \leq 0$ and $x(n)$ belongs to class $\mathfrak{c}_2$}Otherwise, the weight vector of the perceptron is updated in accordance with the rule
w(n + 1) = w(n) - \eta(n)x(n) \text{ if } w^Tx(n) > 0 \text{ and } x(n) \text{ belongs to class }\mathfrak{c}_2w(n + 1) = w(n) + \eta(n)x(n) \text{ if } w^Tx(n) \leq 0 \text{ and } x(n) \text{ belongs to class }\mathfrak{c}_1- Initialisation. Set
w(0)=0. perform the following computations for
time stepn = 1, 2,... - Activation. At time step
n, activate the perceptron by applying continuous-valued input vectorx(n)and desired responsed(n). - Computation of Actual Response. Compute the actual response of the perceptron:
y(n) = sgn[w^T(n)x(n)]where sgn(\cdot) is the signum function.
4. Adaptation of Weight Vector. Update the weight vector of the perceptron:
w(n+1)=w(n)+\eta[d(n)-y(n)]x(n)
d(n) = \begin{cases}
+1 &\text{if $x(n)$ belongs to class $\mathfrak{c_1}$}\\
-1 &\text{if $x(n)$ belongs to class $\mathfrak{c_2}$}
\end{cases}
- Continuation. Increment time step
nby one and go back to step 2.
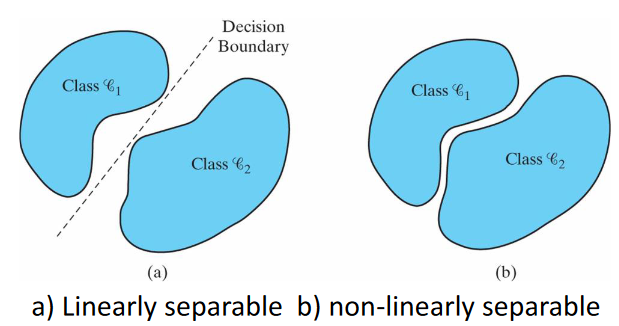
- Guarantees convergence provided
- Patterns are linearly separable
- Non-overlapping classes
- Linear separation boundary
- Learning rate not too high
- Patterns are linearly separable
- Two conflicting requirements
- Averaging of past inputs to provide stable weight estimates
- Small eta
- Fast adaptation with respect to real changes in the underlying distribution of process responsible for
x- Large eta
- Averaging of past inputs to provide stable weight estimates