vault backup: 2023-05-26 06:37:13
Affected files: .obsidian/graph.json .obsidian/workspace-mobile.json .obsidian/workspace.json STEM/AI/Ethics.md STEM/AI/Neural Networks/Activation Functions.md STEM/AI/Neural Networks/CNN/CNN.md STEM/AI/Neural Networks/Deep Learning.md STEM/AI/Neural Networks/MLP/Back-Propagation.md STEM/AI/Neural Networks/MLP/MLP.md STEM/AI/Neural Networks/Neural Networks.md STEM/AI/Neural Networks/Properties+Capabilities.md STEM/AI/Neural Networks/RNN/LSTM.md STEM/AI/Neural Networks/RNN/RNN.md STEM/AI/Neural Networks/RNN/VQA.md STEM/AI/Neural Networks/SLP/SLP.md STEM/AI/Neural Networks/Training.md STEM/AI/Neural Networks/Transformers/Attention.md STEM/AI/Neural Networks/Transformers/LLM.md STEM/AI/Neural Networks/Transformers/Transformers.md STEM/Signal Proc/System Classes.md STEM/img/back-prop-equations.png STEM/img/back-prop-weight-changes.png STEM/img/back-prop1.png STEM/img/back-prop2.png STEM/img/cnn+lstm.png STEM/img/deep-digit-classification.png STEM/img/deep-loss-function.png STEM/img/llm-family-tree.png STEM/img/lstm-slp.png STEM/img/lstm.png STEM/img/matrix-dot-product.png STEM/img/ml-dl.png STEM/img/photo-tensor.png STEM/img/relu.png STEM/img/rnn-input.png STEM/img/rnn-recurrence.png STEM/img/slp-arch.png STEM/img/threshold-activation.png STEM/img/transformer-arch.png STEM/img/vqa-block.png
26
AI/Ethics.md
Normal file
@ -0,0 +1,26 @@
|
|||||||
|
# Fair
|
||||||
|
- Democracy
|
||||||
|
- Board-level
|
||||||
|
- Focus groups
|
||||||
|
- Committees
|
||||||
|
- Guidance for best practices
|
||||||
|
- Consider all stakeholders and impacted social groups
|
||||||
|
- Within system and the data
|
||||||
|
|
||||||
|
# Accountable
|
||||||
|
- Not moral decision-makers
|
||||||
|
- Need owners with checks
|
||||||
|
- Consider impact of system outcomes
|
||||||
|
- Determine where and when human intervention and approval required
|
||||||
|
|
||||||
|
# Private & Secure
|
||||||
|
- Data management and governance are critical
|
||||||
|
- GDPR
|
||||||
|
|
||||||
|
# Explainable & Transparent
|
||||||
|
- Protect reputation, build trust
|
||||||
|
- Demonstrate AI purpose, limitations, risks
|
||||||
|
- Avoid masking interactions with AI
|
||||||
|
|
||||||
|
# Human-Centric & Socially Beneficial
|
||||||
|
- Social and economic benefit to society
|
||||||
@ -1,7 +1,24 @@
|
|||||||
## Sigmoid
|
- Limits output values
|
||||||
|
- Squashing function
|
||||||
|
|
||||||
|
# Threshold
|
||||||
|
- For binary functions
|
||||||
|
- Not differentiable
|
||||||
|
- Sharp rise
|
||||||
|
- *Heaviside function*
|
||||||
|
- Unipolar
|
||||||
|
- 0 <-> +1
|
||||||
|
- Bipolar
|
||||||
|
- -1 <-> +1
|
||||||
|
|
||||||
|
![[threshold-activation.png]]
|
||||||
|
|
||||||
|
# Sigmoid
|
||||||
- Logistic function
|
- Logistic function
|
||||||
- Normalises
|
- Normalises
|
||||||
- Introduces non-linearity
|
- Introduces non-linearity
|
||||||
|
- Alternative is $tanh$
|
||||||
|
- -1 <-> +1
|
||||||
- Easy to take derivative
|
- Easy to take derivative
|
||||||
$$\frac d {dx} \sigma(x)=
|
$$\frac d {dx} \sigma(x)=
|
||||||
\frac d {dx} \left[
|
\frac d {dx} \left[
|
||||||
@ -30,3 +47,10 @@ $$\frac{dy}{dx}=\frac d {dx}\left(\frac u v\right)$$
|
|||||||
|
|
||||||
$$\frac{dy}{dx}=
|
$$\frac{dy}{dx}=
|
||||||
\frac {v \frac d {dx}(u) - u\frac d {dx}(v)} {v^2}$$
|
\frac {v \frac d {dx}(u) - u\frac d {dx}(v)} {v^2}$$
|
||||||
|
|
||||||
|
# ReLu
|
||||||
|
Rectilinear
|
||||||
|
- For deep networks
|
||||||
|
- $y=max(0,x)$
|
||||||
|
|
||||||
|
![[relu.png]]
|
||||||
0
AI/Neural Networks/CNN/CNN.md
Normal file
47
AI/Neural Networks/Deep Learning.md
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
![[deep-digit-classification.png]]
|
||||||
|
|
||||||
|
# Loss Function
|
||||||
|
Objective Function
|
||||||
|
|
||||||
|
- [[Back-Propagation]]
|
||||||
|
- Difference between predicted and target outputs
|
||||||
|
![[deep-loss-function.png]]
|
||||||
|
|
||||||
|
- Test accuracy worse than train accuracy = overfitting
|
||||||
|
- Dense = fully connected
|
||||||
|
- Automates feature engineering
|
||||||
|
|
||||||
|
![[ml-dl.png]]
|
||||||
|
|
||||||
|
These are the two essential characteristics of how deep learning learns from data: the incremental, layer-by-layer way in which increasingly complex representations are developed, and the fact that these intermediate incremental representations are learned jointly, each layer being updated to follow both the representational needs of the layer above and the needs of the layer below. Together, these two properties have made deep learning vastly more successful than previous approaches to machine learning.
|
||||||
|
|
||||||
|
# Steps
|
||||||
|
Structure defining
|
||||||
|
Compilation
|
||||||
|
- Loss function
|
||||||
|
- Metric of difference between output and target
|
||||||
|
- Optimiser
|
||||||
|
- How network will update
|
||||||
|
- Metrics to monitor
|
||||||
|
- Testing and training
|
||||||
|
Data preprocess
|
||||||
|
- Reshape input frame into linear array
|
||||||
|
- Categorically encode labels
|
||||||
|
Fit
|
||||||
|
Predict
|
||||||
|
Evaluate
|
||||||
|
|
||||||
|
# Data Structure
|
||||||
|
- Tensor flow = channels last
|
||||||
|
- (samples, height, width, channels)
|
||||||
|
- Vector data
|
||||||
|
- 2D tensors of shape (samples, features)
|
||||||
|
- Time series data or sequence data
|
||||||
|
- 3D tensors of shape (samples, timesteps, features)
|
||||||
|
- Images
|
||||||
|
- 4D tensors of shape (samples, height, width, channels) or (samples, channels, height, Width)
|
||||||
|
- Video
|
||||||
|
- 5D tensors of shape (samples, frames, height, width, channels) or (samples, frames, channels , height, width)
|
||||||
|
|
||||||
|
![[photo-tensor.png]]
|
||||||
|
![[matrix-dot-product.png]]
|
||||||
@ -45,7 +45,7 @@ $$\Delta w_{ji}(n)=
|
|||||||
$$\Delta w_{ji}(n)=
|
$$\Delta w_{ji}(n)=
|
||||||
\eta\delta_j(n)y_i(n)$$
|
\eta\delta_j(n)y_i(n)$$
|
||||||
## Gradients
|
## Gradients
|
||||||
#### Output
|
#### Output Local
|
||||||
$$\delta_j(n)=-\frac{\partial\mathfrak E (n)}{\partial v_j(n)}$$
|
$$\delta_j(n)=-\frac{\partial\mathfrak E (n)}{\partial v_j(n)}$$
|
||||||
$$=-
|
$$=-
|
||||||
\frac{\partial\mathfrak E(n)}{\partial e_j(n)}
|
\frac{\partial\mathfrak E(n)}{\partial e_j(n)}
|
||||||
@ -56,7 +56,7 @@ e_j(n)\cdot
|
|||||||
\varphi_j'(v_j(n))
|
\varphi_j'(v_j(n))
|
||||||
$$
|
$$
|
||||||
|
|
||||||
#### Local
|
#### Hidden Local
|
||||||
$$\delta_j(n)=-
|
$$\delta_j(n)=-
|
||||||
\frac{\partial\mathfrak E (n)}{\partial y_j(n)}
|
\frac{\partial\mathfrak E (n)}{\partial y_j(n)}
|
||||||
\frac{\partial y_j(n)}{\partial v_j(n)}$$
|
\frac{\partial y_j(n)}{\partial v_j(n)}$$
|
||||||
@ -77,7 +77,7 @@ $$\Delta w_{ji}(n)=\eta\cdot\delta_j(n)\cdot y_i(n)$$
|
|||||||
- 4 partial derivatives
|
- 4 partial derivatives
|
||||||
1. Sum of squared errors WRT error in one output node
|
1. Sum of squared errors WRT error in one output node
|
||||||
2. Error WRT output $y$
|
2. Error WRT output $y$
|
||||||
3. Output Y WRT Pre-activation function sum
|
3. Output $y$ WRT Pre-activation function sum
|
||||||
4. Pre-activation function sum WRT weight
|
4. Pre-activation function sum WRT weight
|
||||||
- Other weights constant, goes to zero
|
- Other weights constant, goes to zero
|
||||||
- Leaves just $y_i$
|
- Leaves just $y_i$
|
||||||
@ -105,3 +105,11 @@ $$\Delta w_{ji}(n)=\eta\cdot\delta_j(n)\cdot y_i(n)$$
|
|||||||
|
|
||||||
![[mlp-global-minimum.png]]
|
![[mlp-global-minimum.png]]
|
||||||
|
|
||||||
|
![[back-prop1.png]]
|
||||||
|
![[back-prop2.png]]
|
||||||
|
|
||||||
|
![[back-prop-equations.png]]
|
||||||
|
|
||||||
|
$w^+_5=w_5-\eta\cdot\frac{\partial E_{total}}{\partial w_5}$
|
||||||
|
|
||||||
|
![[back-prop-weight-changes.png]]
|
||||||
36
AI/Neural Networks/Neural Networks.md
Normal file
@ -0,0 +1,36 @@
|
|||||||
|
- Massively parallel, distributed processor
|
||||||
|
- Natural propensity for storing experiential knowledge
|
||||||
|
|
||||||
|
# Resembles Brain
|
||||||
|
|
||||||
|
- Knowledge acquired from by network through learning
|
||||||
|
- Interneuron connection strengths store acquired knowledge
|
||||||
|
- Synaptic weights
|
||||||
|
|
||||||
|
![[slp-arch.png]]
|
||||||
|
|
||||||
|
A neural network is a directed graph consisting of nodes with interconnecting synaptic and activation links, and is characterised by four properties
|
||||||
|
|
||||||
|
1. Each neuron is represented by a set of linear synaptic links, an externally applied bias, and a possibly nonlinear activation link. The bias is represented by a synaptic link connected to an input fixed at +1
|
||||||
|
2. The synaptic links of a neuron weight their respective input signals
|
||||||
|
3. The weighted sum of the input signals defines the induced local field of the neuron in question
|
||||||
|
4. The activation link squashes the induced local field of the neuron to produce an output
|
||||||
|
|
||||||
|
# Knowledge
|
||||||
|
|
||||||
|
*Knowledge refers to stored information or models used by a person or machine to interpret, predict, and appropriately respond to the outside world*
|
||||||
|
|
||||||
|
Made up of:
|
||||||
|
1. The known world state
|
||||||
|
- Represented by facts about what is and what has been known
|
||||||
|
- Prior information
|
||||||
|
2. Observations of the world
|
||||||
|
- Usually inherently noisy
|
||||||
|
- Measurement error
|
||||||
|
- Pool of information used to train
|
||||||
|
|
||||||
|
- Can be labelled or not
|
||||||
|
- (Un-)Supervised
|
||||||
|
|
||||||
|
*Knowledge representation of the surrounding environment is defined by the values taken on by the free parameters of the network*
|
||||||
|
- Synaptic weights and biases
|
||||||
@ -14,12 +14,31 @@
|
|||||||
# Adaptivity
|
# Adaptivity
|
||||||
- Synaptic weights
|
- Synaptic weights
|
||||||
- Can be easily retrained
|
- Can be easily retrained
|
||||||
- Can operate in non-stationary environments
|
- Stationary environment
|
||||||
|
- Essential statistics can be learned
|
||||||
|
- Model can then be frozen
|
||||||
|
- Non-stationary environments
|
||||||
- Can change weights in real-time
|
- Can change weights in real-time
|
||||||
- In general, more adaptive = more robust
|
- In general, more adaptive = more robust
|
||||||
- Not always though
|
- Not always though
|
||||||
- Short time-constant system may be thrown by short-time spurious disturbances
|
- Short time-constant system may be thrown by short-time spurious disturbances
|
||||||
- Stability-plasticity dilemma
|
- Stability-plasticity dilemma
|
||||||
|
- Not equipped to track statistical variations
|
||||||
|
- Adaptive system
|
||||||
|
- Linear adaptive filter
|
||||||
|
- Linear combiner
|
||||||
|
- Single neuron operating in linear mode
|
||||||
|
- Mature applications
|
||||||
|
- Nonlinear adaptive filters
|
||||||
|
- Less mature
|
||||||
|
- Environments typically considered pseudo-stationary
|
||||||
|
- Speech stationary over short windows
|
||||||
|
- Retrain network at regular intervals to account for fluctuations
|
||||||
|
- E.g. stock market
|
||||||
|
- Train network on short time window
|
||||||
|
- Add new data and pop old
|
||||||
|
- Slide window
|
||||||
|
- Retrain network
|
||||||
|
|
||||||
# Evidential Response
|
# Evidential Response
|
||||||
- Decisions are made with evidence not just declared
|
- Decisions are made with evidence not just declared
|
||||||
@ -51,3 +70,29 @@
|
|||||||
# Neurobiological Analogy
|
# Neurobiological Analogy
|
||||||
- Design analogous to brain
|
- Design analogous to brain
|
||||||
- Already a demonstrable fault-tolerant, powerful, fast, parallel processor
|
- Already a demonstrable fault-tolerant, powerful, fast, parallel processor
|
||||||
|
|
||||||
|
- To slight changes
|
||||||
|
- Rotation of target in images
|
||||||
|
- Doppler shift in radar
|
||||||
|
- Network needs to be invariant to these transformations
|
||||||
|
|
||||||
|
# Invariance
|
||||||
|
1. Invariance by Structure
|
||||||
|
- Synaptic connections created so that transformed input produces same output
|
||||||
|
- Set same weight for neurons of some geometric relationship to image
|
||||||
|
- Same distance from centre e.g.
|
||||||
|
- Number of connections becomes prohibitively large
|
||||||
|
2. Invariance by Training
|
||||||
|
- Train on different views/transformations
|
||||||
|
- Take advantage of inherent pattern classification abilities
|
||||||
|
- Training for invariance for one object is not necessarily going to train other classes for invariance
|
||||||
|
- Extra load on network to do more training
|
||||||
|
- Exacerbated with high dimensionality
|
||||||
|
3. Invariant Feature Space
|
||||||
|
- Extract invariant features
|
||||||
|
- Use network as classifier
|
||||||
|
- Relieves burden on network to achieve invariance
|
||||||
|
- Complicated decision boundaries
|
||||||
|
- Number of features applied to network reduced
|
||||||
|
- Invariance ensured
|
||||||
|
- Required prior knowledge
|
||||||
7
AI/Neural Networks/RNN/LSTM.md
Normal file
@ -0,0 +1,7 @@
|
|||||||
|
Long Short Term Memory
|
||||||
|
|
||||||
|
- More general form of [[RNN]]
|
||||||
|
- Explicitly encode memory state, C
|
||||||
|
|
||||||
|
![[lstm.png]]
|
||||||
|
![[lstm-slp.png]]
|
||||||
17
AI/Neural Networks/RNN/RNN.md
Normal file
@ -0,0 +1,17 @@
|
|||||||
|
Recurrent Neural Network
|
||||||
|
|
||||||
|
- Hard to train on long sequences
|
||||||
|
- Weights hold memory
|
||||||
|
- Implicit
|
||||||
|
- Lots to remember
|
||||||
|
|
||||||
|
## Text Analysis
|
||||||
|
- Train sequences of text character-by-character
|
||||||
|
- Maintains state vector representing data up to current token
|
||||||
|
- Combines state vector with next token to create new vector
|
||||||
|
- In theory, info from one token can propagate arbitrarily far down the sequence
|
||||||
|
- In practice suffers from vanishing gradient
|
||||||
|
- Can't extract precise information about previous tokens
|
||||||
|
|
||||||
|
![[rnn-input.png]]
|
||||||
|
![[rnn-recurrence.png]]
|
||||||
19
AI/Neural Networks/RNN/VQA.md
Normal file
@ -0,0 +1,19 @@
|
|||||||
|
Visual Question Answering
|
||||||
|
|
||||||
|
- Combine visual with text sequence
|
||||||
|
- [[CNN]] + [[LSTM]]
|
||||||
|
- Generate text from images
|
||||||
|
- Automatic scene description
|
||||||
|
- Cross-modal
|
||||||
|
|
||||||
|
![[cnn+lstm.png]]
|
||||||
|
- Word embedding not character
|
||||||
|
|
||||||
|
# Freeform
|
||||||
|
- Encode facts with two text streams
|
||||||
|
![[vqa-block.png]]
|
||||||
|
# Limitations
|
||||||
|
- Repetitive answers
|
||||||
|
- Not much variation
|
||||||
|
- No creativity
|
||||||
|
- Wont generalise beyond taught concepts
|
||||||
13
AI/Neural Networks/Training.md
Normal file
@ -0,0 +1,13 @@
|
|||||||
|
# Modes
|
||||||
|
## Sequential
|
||||||
|
- Apply changes after each train pattern
|
||||||
|
- Less local storage for each synaptic connection
|
||||||
|
- Search in weight space stochastic
|
||||||
|
- Patterns presented to network in random order
|
||||||
|
- Less likely to fall into local minima
|
||||||
|
- Difficult to establish theoretical conditions for convergence
|
||||||
|
|
||||||
|
## Batch
|
||||||
|
- Apply changes at the end
|
||||||
|
- Accurate estimate of gradient vector
|
||||||
|
- Can guarantee convergence to local minimum
|
||||||
52
AI/Neural Networks/Transformers/Attention.md
Normal file
@ -0,0 +1,52 @@
|
|||||||
|
- Meant to mimic cognitive attention
|
||||||
|
- Picks out relevant bits of information
|
||||||
|
- Use gradient descent
|
||||||
|
- Used in 90s
|
||||||
|
- Multiplicative modules
|
||||||
|
- Sigma pi units
|
||||||
|
- Hyper-networks
|
||||||
|
- Draw from relevant state at any preceding point along sequence
|
||||||
|
- Addresses [[RNN]]s vanishing gradient issues
|
||||||
|
- [[LSTM]] tends to poorly preserve far back knowledge
|
||||||
|
- Attention layer access all previous states and weighs according to learned measure of relevance
|
||||||
|
- Allows referring arbitrarily far back to relevant tokens
|
||||||
|
- Can be addd to [[RNN]]s
|
||||||
|
- In 2016, a new type of highly parallelisable _decomposable attention_ was successfully combined with a feedforward network
|
||||||
|
- Attention useful in of itself, not just with [[RNN]]s
|
||||||
|
- [[Transformers]] use attention without recurrent connections
|
||||||
|
- Process all tokens simultaneously
|
||||||
|
- Calculate attention weights in successive layers
|
||||||
|
|
||||||
|
# Scaled Dot-Product
|
||||||
|
- Calculate attention weights between all tokens at once
|
||||||
|
- Learn 3 weight matrices
|
||||||
|
- Query
|
||||||
|
- $W_Q$
|
||||||
|
- Key
|
||||||
|
- $W_K$
|
||||||
|
- Value
|
||||||
|
- $W_V$
|
||||||
|
- Word vectors
|
||||||
|
- For each token, $i$, input word embedding, $x_i$
|
||||||
|
- Multiply with each of above to produce vector
|
||||||
|
- Query Vector
|
||||||
|
- $q_i=x_iW_Q$
|
||||||
|
- Key Vector
|
||||||
|
- $k_i=x_iW_K$
|
||||||
|
- Value Vector
|
||||||
|
- $v_i=x_iW_V$
|
||||||
|
- Attention vector
|
||||||
|
- Query and key vectors between token $i$ and $j$
|
||||||
|
- $a_{ij}=q_i\cdot k_j$
|
||||||
|
- Divided by root of dimensionality of key vectors
|
||||||
|
- $\sqrt{d_k}$
|
||||||
|
- Pass through softmax to normalise
|
||||||
|
- $W_Q$ and $W_K$ are different matrices
|
||||||
|
- Attention can be non-symmetric
|
||||||
|
- Token $i$ attends to $j$ ($q_i\cdot k_j$ is large)
|
||||||
|
- Doesn't imply that $j$ attends to $i$ ($q_j\cdot k_i$ can be small)
|
||||||
|
- Output for token $i$ is weighted sum of value vectors of all tokens weighted by $a_{ij}$
|
||||||
|
- Attention from token $i$ to each other token
|
||||||
|
- $Q, K, V$ are matrices where $i$th row are vectors $q_i, k_i, v_i$ respectively
|
||||||
|
$$\text{Attention}(Q,K,V)=\text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V$$
|
||||||
|
- softmax taken over horizontal axis
|
||||||
16
AI/Neural Networks/Transformers/LLM.md
Normal file
@ -0,0 +1,16 @@
|
|||||||
|
# Properties
|
||||||
|
## Pre-training Datasets
|
||||||
|
|
||||||
|
## Scaling Laws
|
||||||
|
|
||||||
|
## Emergent Abilities
|
||||||
|
|
||||||
|
## Hallucination
|
||||||
|
|
||||||
|
# Architectures
|
||||||
|
Mostly [[Transformers]]
|
||||||
|
|
||||||
|
## GPT
|
||||||
|
Generative Pre-trained [[Transformers]]
|
||||||
|
|
||||||
|
![[llm-family-tree.png]]
|
||||||
39
AI/Neural Networks/Transformers/Transformers.md
Normal file
@ -0,0 +1,39 @@
|
|||||||
|
- [[Attention|Self-attention]]
|
||||||
|
- Weighting significance of parts of the input
|
||||||
|
- Including recursive output
|
||||||
|
- Similar to [[RNN]]s
|
||||||
|
- Process sequential data
|
||||||
|
- Translation & text summarisation
|
||||||
|
- Differences
|
||||||
|
- Process input all at once
|
||||||
|
- Largely replaced [[LSTM]] and gated recurrent units (GRU) which had attention mechanics
|
||||||
|
- No recurrent structure
|
||||||
|
|
||||||
|
![[transformer-arch.png]]
|
||||||
|
|
||||||
|
## Examples
|
||||||
|
- BERT
|
||||||
|
- Bidirectional Encoder Representations from Transformers
|
||||||
|
- Google
|
||||||
|
- Original GPT
|
||||||
|
|
||||||
|
[transformers-explained-visually-part-1-overview-of-functionality](https://towardsdatascience.com/transformers-explained-visually-part-1-overview-of-functionality-95a6dd460452)
|
||||||
|
# Architecture
|
||||||
|
## Input
|
||||||
|
- Byte-pair encoding tokeniser
|
||||||
|
- Mapped via word embedding into vector
|
||||||
|
- Positional information added
|
||||||
|
|
||||||
|
## Encoder/Decoder
|
||||||
|
- Similar to seq2seq models
|
||||||
|
- Create internal representation
|
||||||
|
- Encoder layers
|
||||||
|
- Create encodings that contain information about which parts of input are relevant to each other
|
||||||
|
- Subsequent encoder layers receive previous encoding layers output
|
||||||
|
- Decoder layers
|
||||||
|
- Takes encodings and does opposite
|
||||||
|
- Uses incorporated textual information to produce output
|
||||||
|
- Has attention to draw information from output of previous decoders before drawing from encoders
|
||||||
|
- Both use [[attention]]
|
||||||
|
- Both use dense layers for additional processing of outputs
|
||||||
|
- Contain residual connections & layer norm steps
|
||||||
44
Signal Proc/System Classes.md
Normal file
@ -0,0 +1,44 @@
|
|||||||
|
# Dynamic vs Algebraic
|
||||||
|
- Dynamic system has "memory", output depends on present and past
|
||||||
|
- Includes diff and/or integral operators with initial conditions
|
||||||
|
- Cap and or inducer
|
||||||
|
- Algebraic
|
||||||
|
- No calculus operators
|
||||||
|
- Output depends only on input
|
||||||
|
|
||||||
|
# Time Invariant vs Time-Varying
|
||||||
|
|
||||||
|
# Continuous vs Discrete time
|
||||||
|
|
||||||
|
# Linear vs Non-Linear
|
||||||
|
|
||||||
|
# Deterministic vs Stochastic
|
||||||
|
- Deterministic
|
||||||
|
- Output fully determined by parameter inputs
|
||||||
|
- Stochastic
|
||||||
|
- Include randomness
|
||||||
|
- Noise/Disturbance
|
||||||
|
- Same inputs can lead to different outputs
|
||||||
|
|
||||||
|
# Lumped vs Distributed parameters
|
||||||
|
- Lumped
|
||||||
|
- Only one independent variable (time $t$)
|
||||||
|
- Typical for electrical systems
|
||||||
|
- $x(t)$
|
||||||
|
- Ordinary differential equations
|
||||||
|
- Distributed
|
||||||
|
- Several independent variables
|
||||||
|
- time, pressure, temperature
|
||||||
|
- Typical for chemical processes and process control
|
||||||
|
-$x(t, P, T)$
|
||||||
|
- Differential partial equations
|
||||||
|
|
||||||
|
# Causal vs Non-Causal
|
||||||
|
- Causal
|
||||||
|
- Output depends only on current and past values
|
||||||
|
- Non-Causal
|
||||||
|
- Output depends on future inputs
|
||||||
|
|
||||||
|
# SISO vs MIMO
|
||||||
|
- Single Input/Single Output
|
||||||
|
- Multiple Input/Multiple Output
|
||||||
BIN
img/back-prop-equations.png
Normal file
|
After 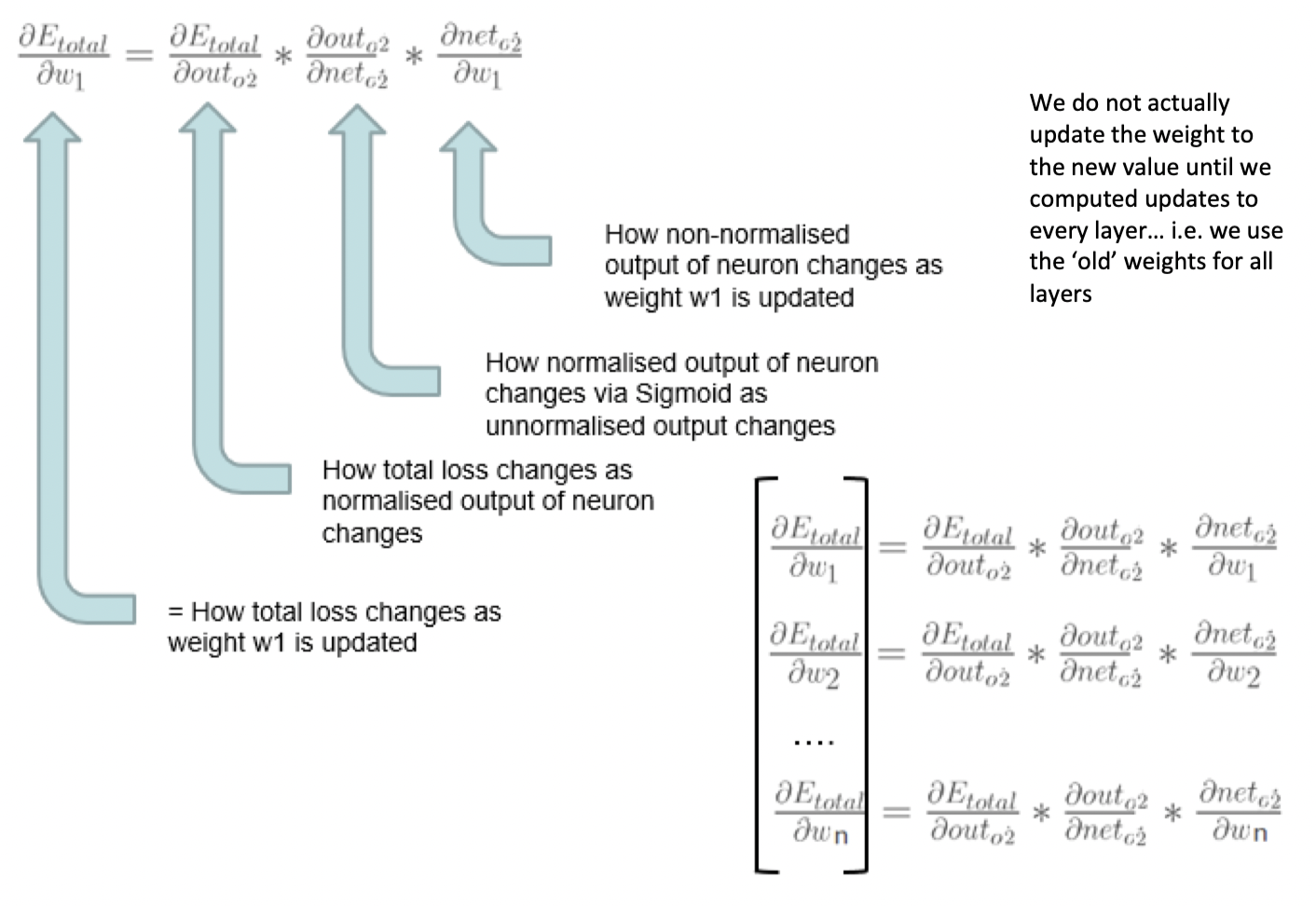
(image error) Size: 813 KiB |
BIN
img/back-prop-weight-changes.png
Normal file
|
After 
(image error) Size: 499 KiB |
BIN
img/back-prop1.png
Normal file
|
After 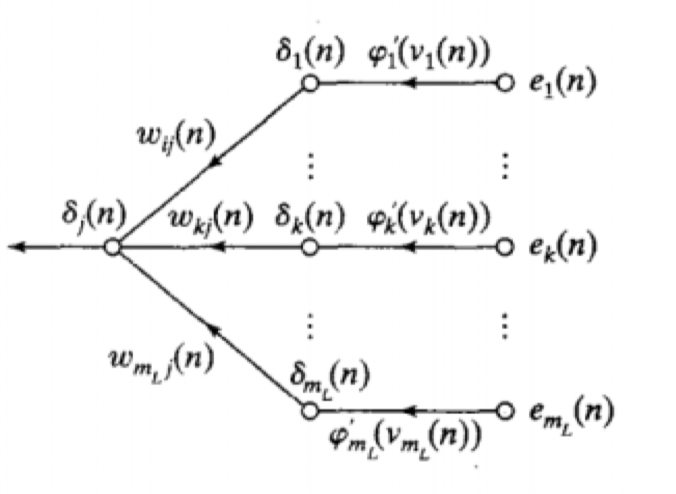
(image error) Size: 311 KiB |
BIN
img/back-prop2.png
Normal file
|
After 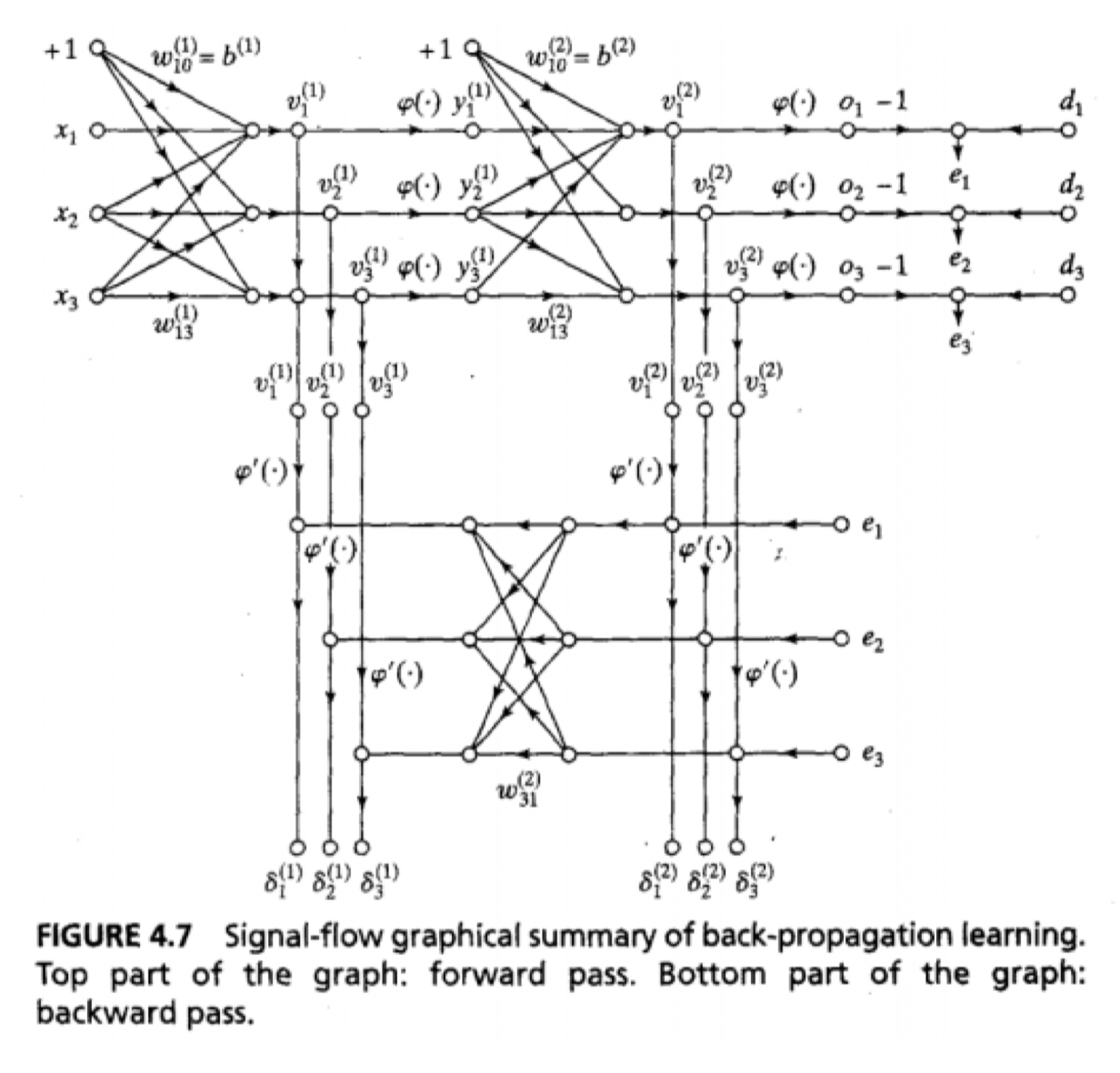
(image error) Size: 1.4 MiB |
BIN
img/cnn+lstm.png
Normal file
|
After 
(image error) Size: 121 KiB |
BIN
img/deep-digit-classification.png
Normal file
|
After 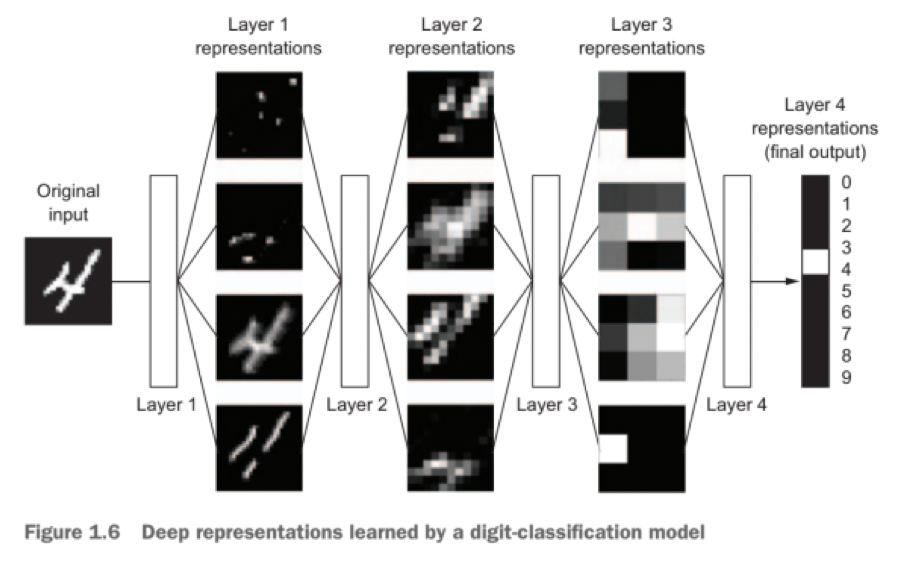
(image error) Size: 487 KiB |
BIN
img/deep-loss-function.png
Normal file
|
After 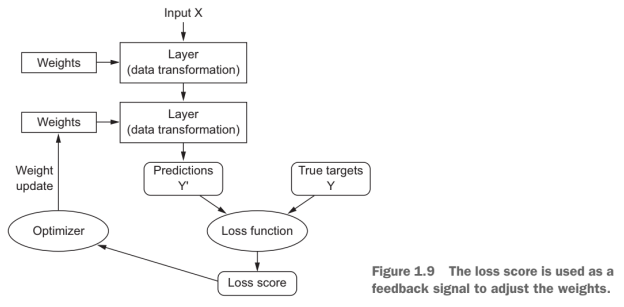
(image error) Size: 38 KiB |
BIN
img/llm-family-tree.png
Normal file
|
After 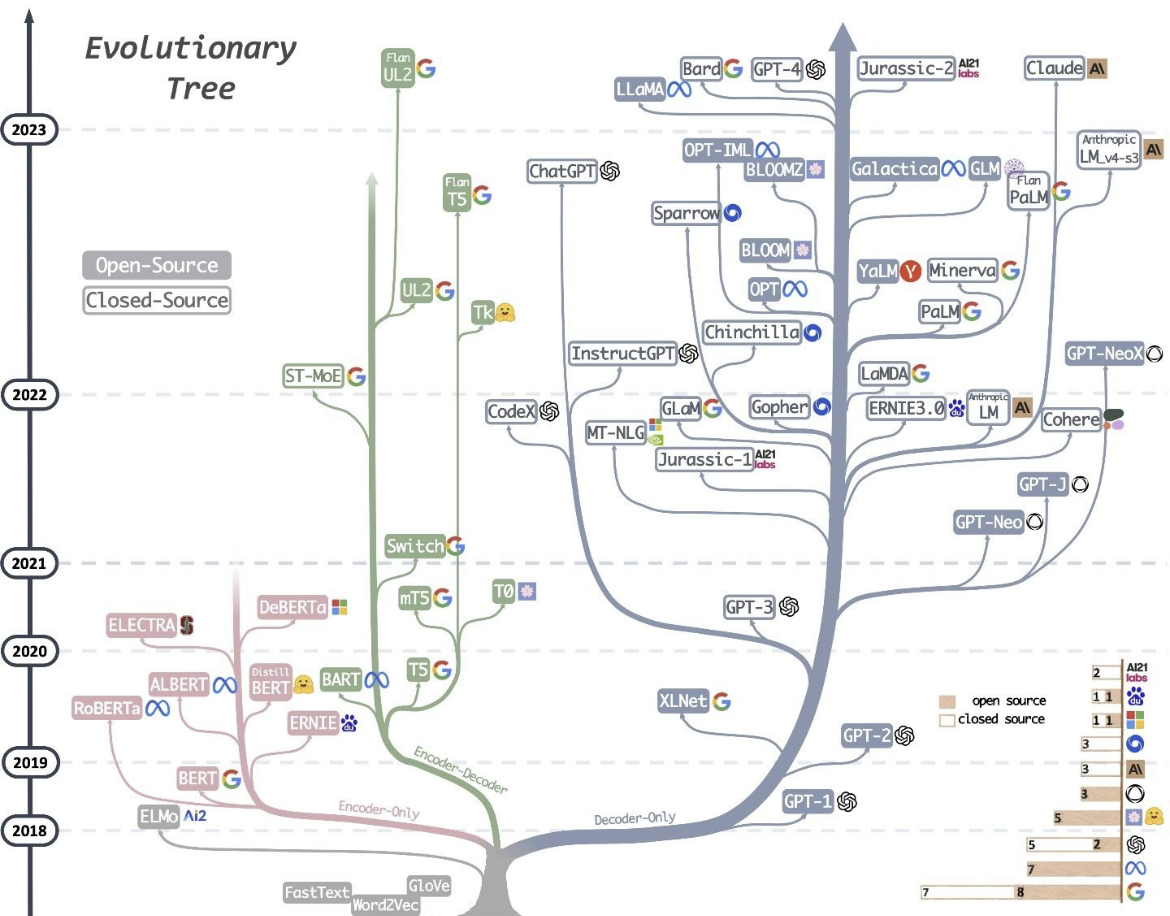
(image error) Size: 859 KiB |
BIN
img/lstm-slp.png
Normal file
|
After 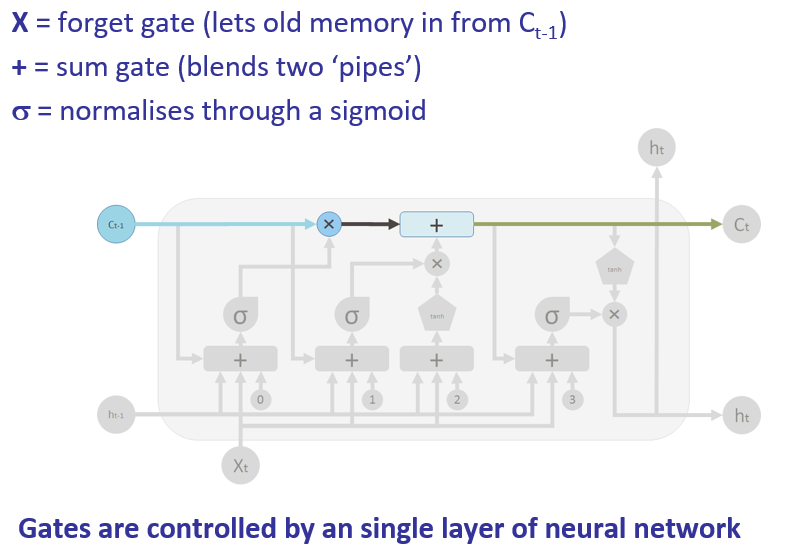
(image error) Size: 59 KiB |
BIN
img/lstm.png
Normal file
|
After 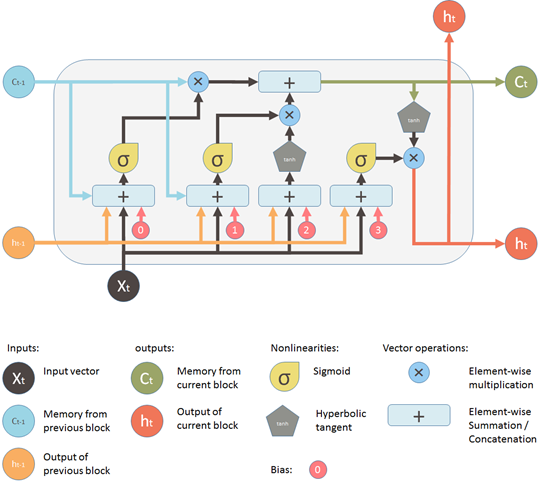
(image error) Size: 84 KiB |
BIN
img/matrix-dot-product.png
Normal file
|
After 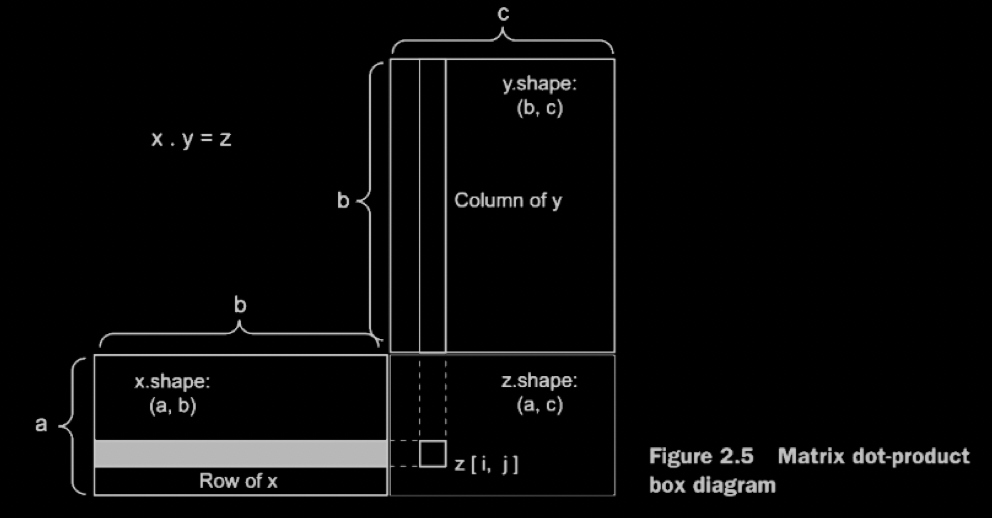
(image error) Size: 181 KiB |
BIN
img/ml-dl.png
Normal file
|
After 
(image error) Size: 284 KiB |
BIN
img/photo-tensor.png
Normal file
|
After 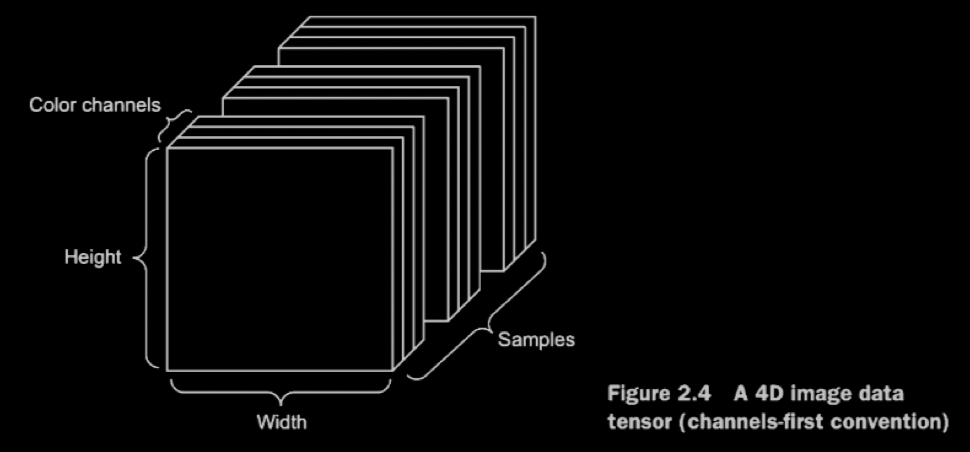
(image error) Size: 201 KiB |
BIN
img/relu.png
Normal file
|
After 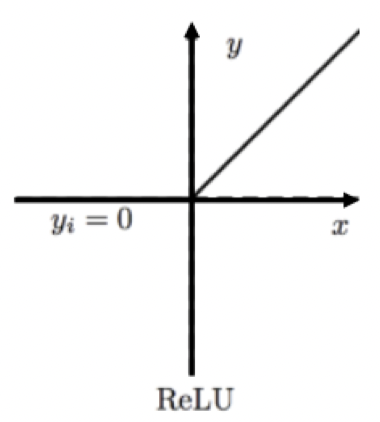
(image error) Size: 82 KiB |
BIN
img/rnn-input.png
Normal file
|
After 
(image error) Size: 96 KiB |
BIN
img/rnn-recurrence.png
Normal file
|
After 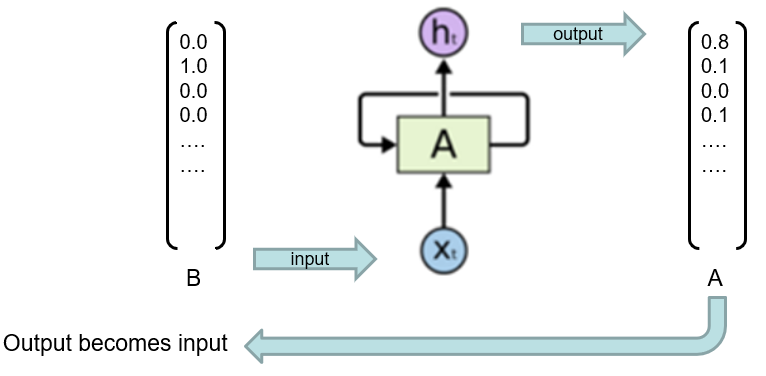
(image error) Size: 36 KiB |
BIN
img/slp-arch.png
|
Before 
(image error) Size: 409 KiB After 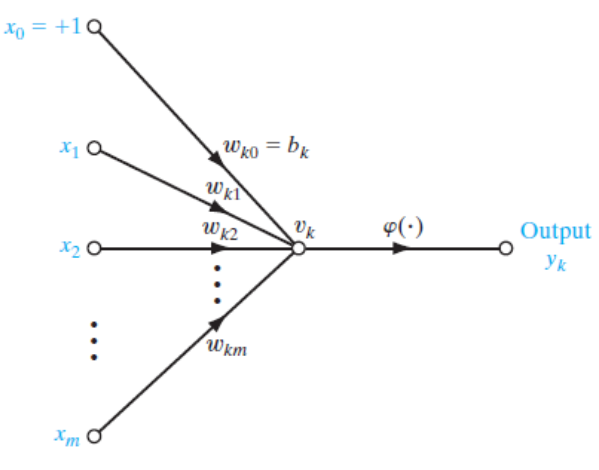
(image error) Size: 45 KiB
|
BIN
img/threshold-activation.png
Normal file
|
After 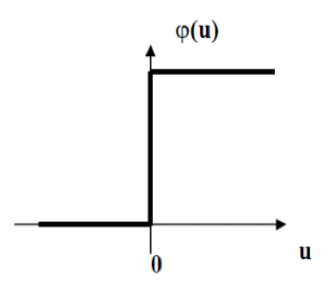
(image error) Size: 39 KiB |
BIN
img/transformer-arch.png
Normal file
|
After (image error) Size: 178 KiB |
BIN
img/vqa-block.png
Normal file
|
After 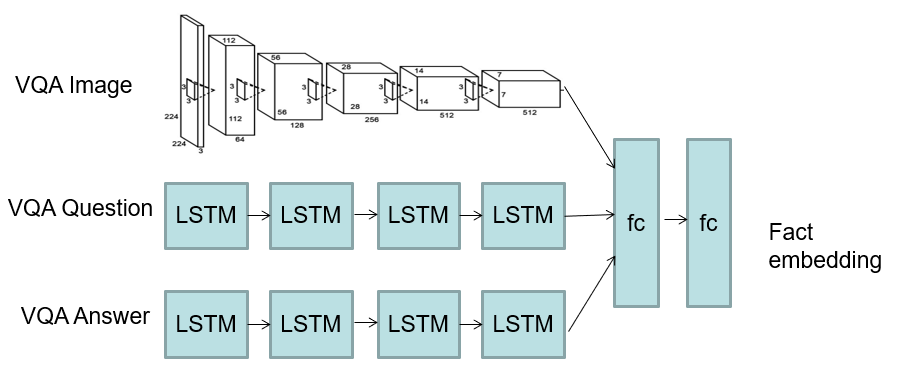
(image error) Size: 39 KiB |