adding layers results
BIN
cars/architecture-investigations/best-barh.png
Normal file
{kind=link}
|
After 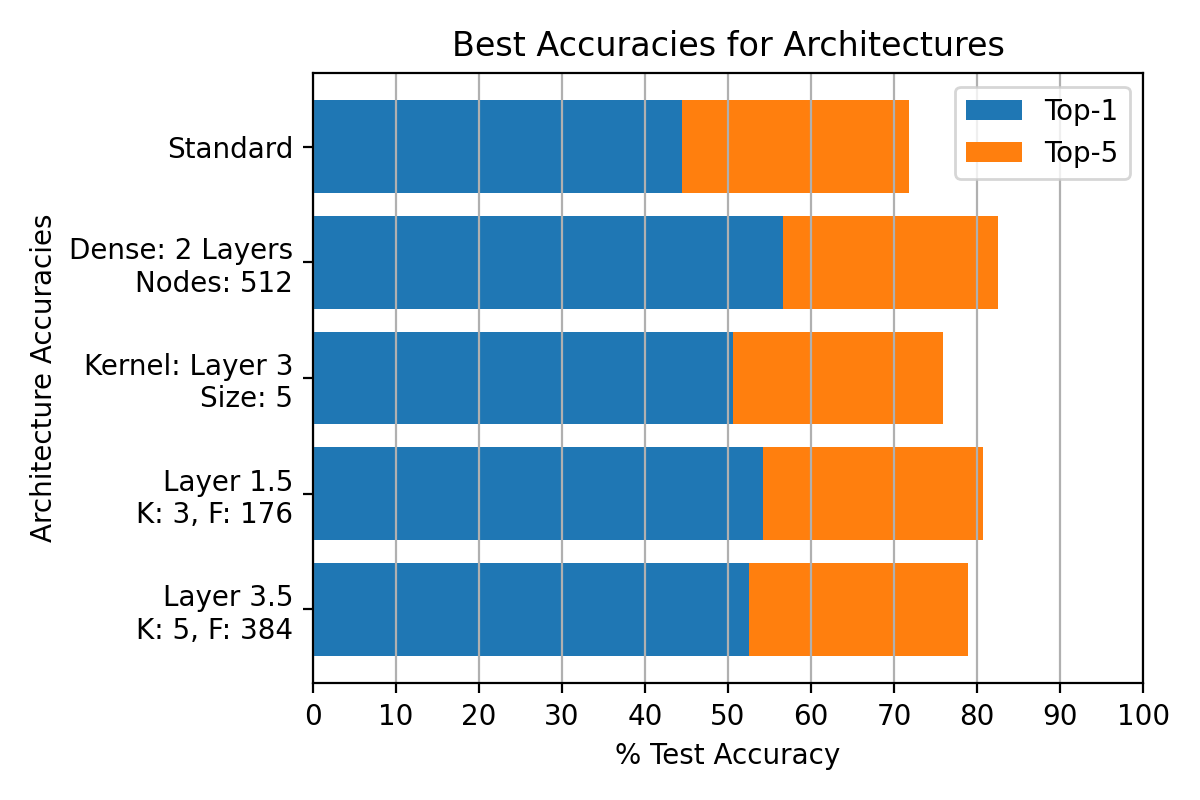
(image error) Size: 51 KiB |
4566
cars/architecture-investigations/best/caffe_output.log
Normal file
197
cars/architecture-investigations/best/conf.csv
Normal file
341
cars/architecture-investigations/best/deploy.prototxt
Normal file
@ -0,0 +1,341 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 5
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
BIN
cars/architecture-investigations/best/large.png
Normal file
{kind=link}
|
After 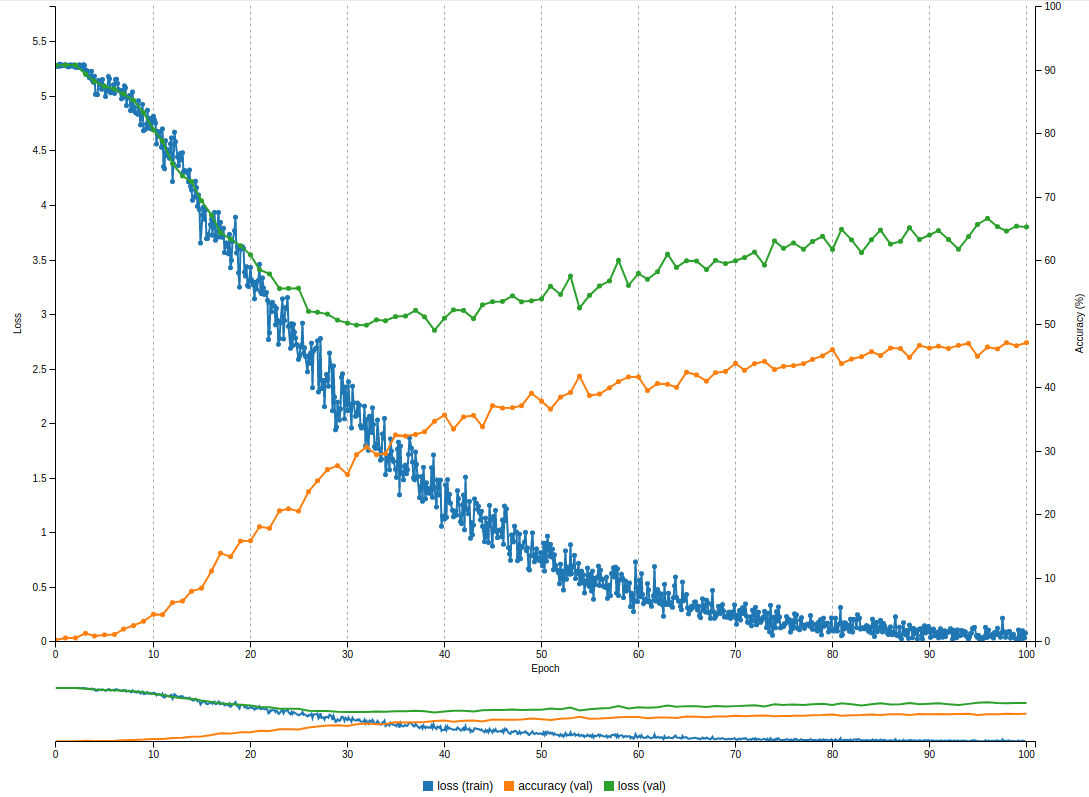
(image error) Size: 122 KiB |
388
cars/architecture-investigations/best/original.prototxt
Normal file
@ -0,0 +1,388 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 5
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
1619
cars/architecture-investigations/best/pred.csv
Normal file
BIN
cars/architecture-investigations/best/small.png
Normal file
{kind=link}
|
After 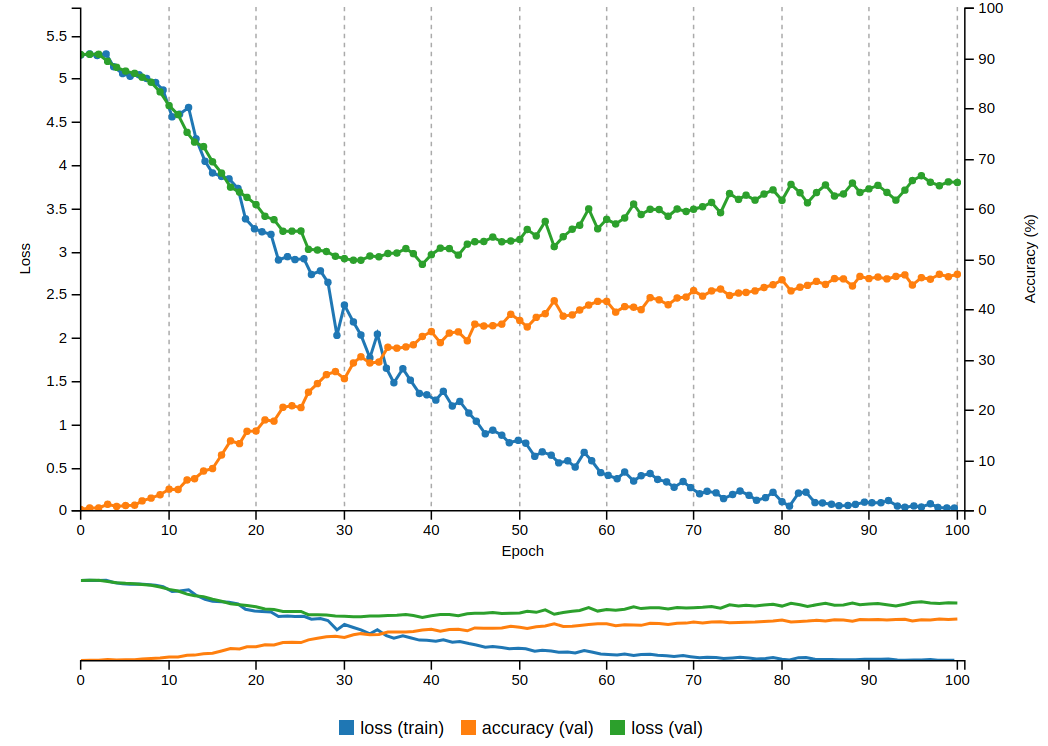
(image error) Size: 102 KiB |
14
cars/architecture-investigations/best/solver.prototxt
Normal file
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
382
cars/architecture-investigations/best/train_val.prototxt
Normal file
@ -0,0 +1,382 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 5
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 7
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 1024
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,488 @@
|
||||
# AlexNet
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
include { stage: "train" }
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
include { stage: "val" }
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 1
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 0.0001
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 1.5
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 0.0001
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 2
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 0.0001
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 3
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 4
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 5
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# DENSE 1
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.005
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# DENSE 2
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.005
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# OUTPUT
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
# Since num_output is unset, DIGITS will automatically set it to the
|
||||
# number of classes in your dataset.
|
||||
# Uncomment this line to set it explicitly:
|
||||
#num_output: 1000
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# STATS
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include { stage: "val" }
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude { stage: "deploy" }
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include { stage: "deploy" }
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 126 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 105 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 124 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 105 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 124 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 104 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 7
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 11
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 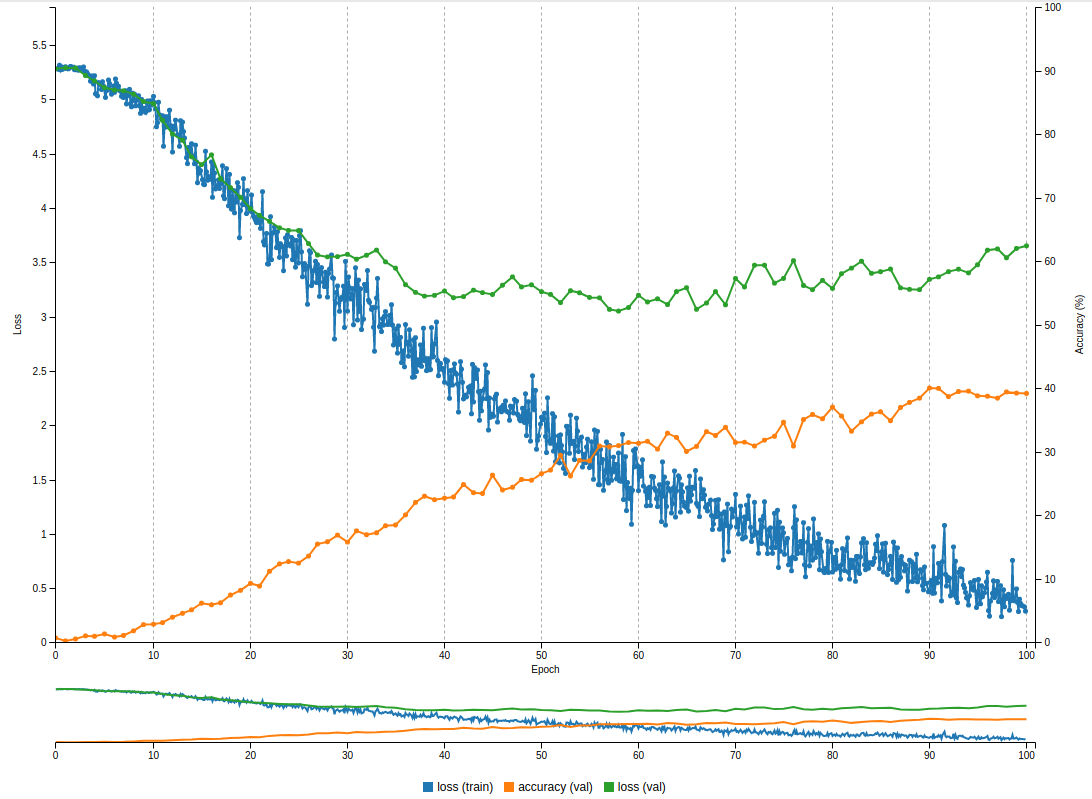
(image error) Size: 130 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 11
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 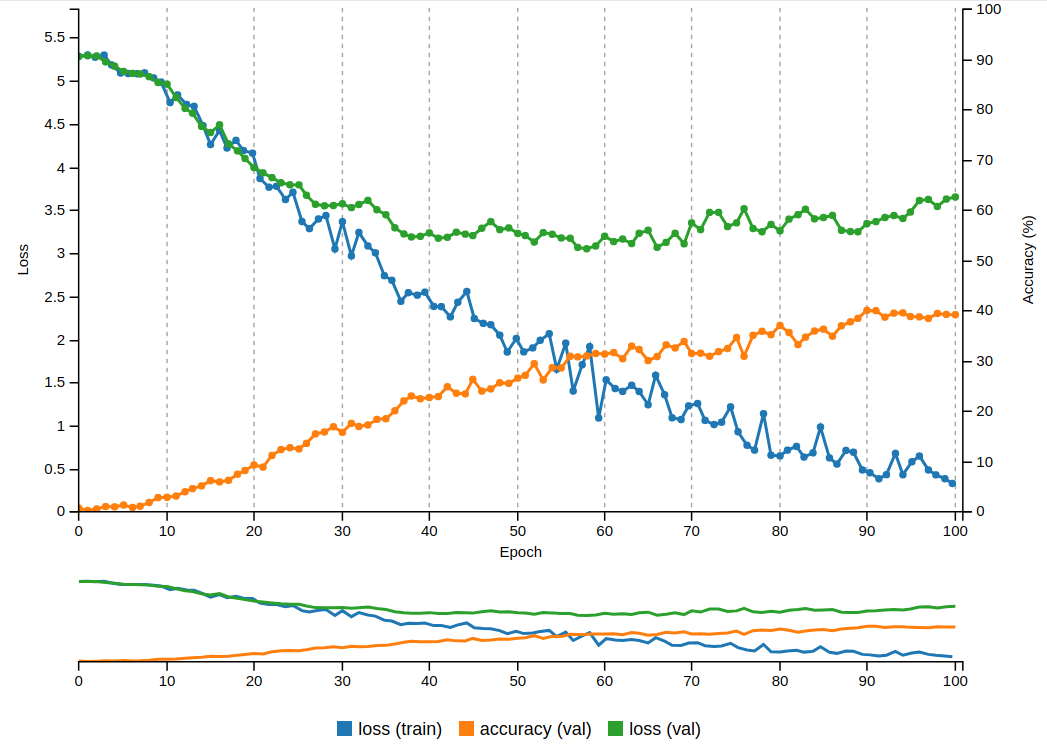
(image error) Size: 108 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 11
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 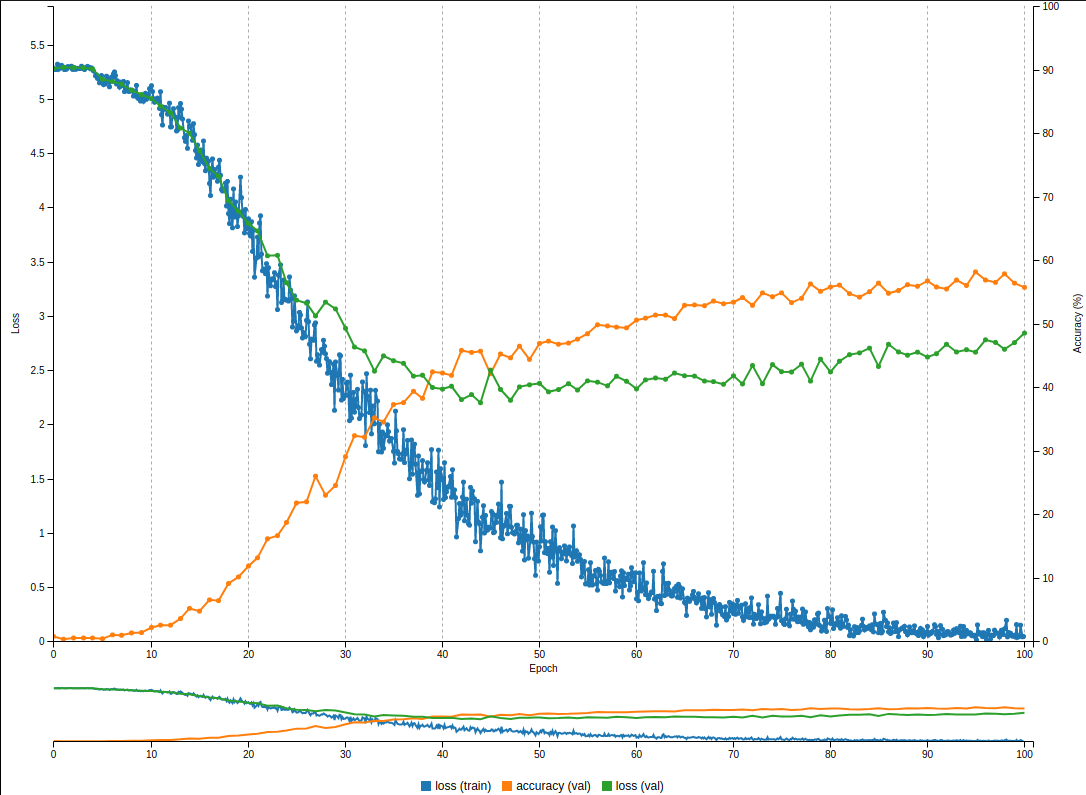
(image error) Size: 120 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 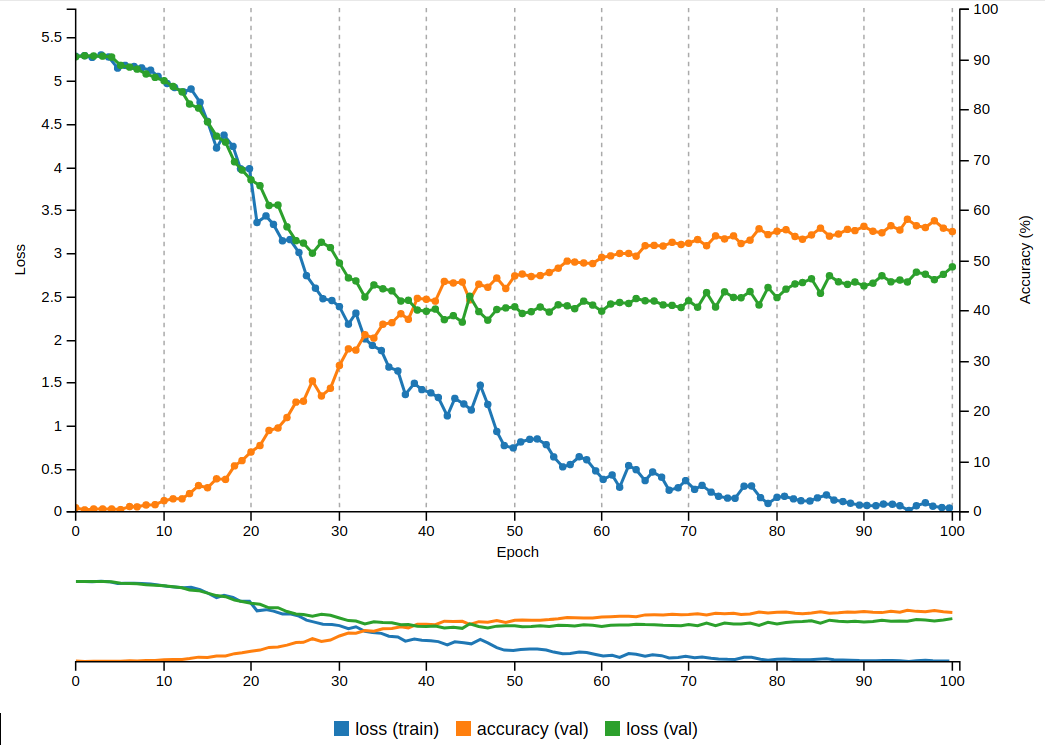
(image error) Size: 103 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 5
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 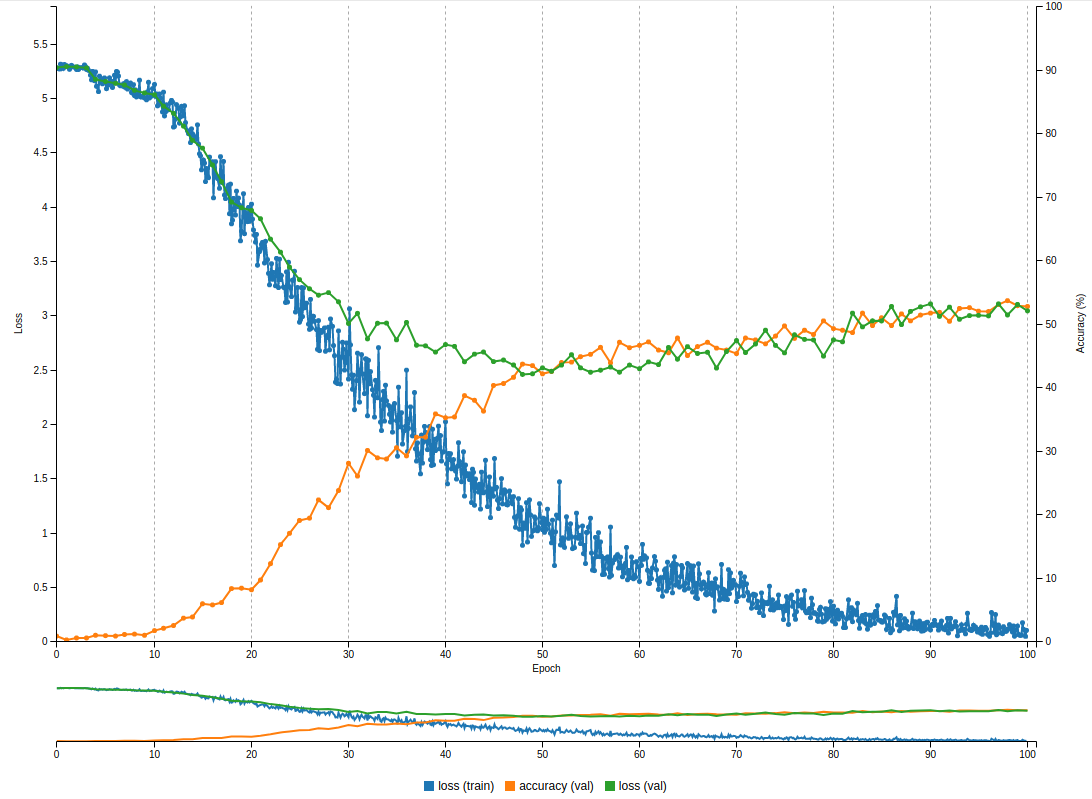
(image error) Size: 124 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 5
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 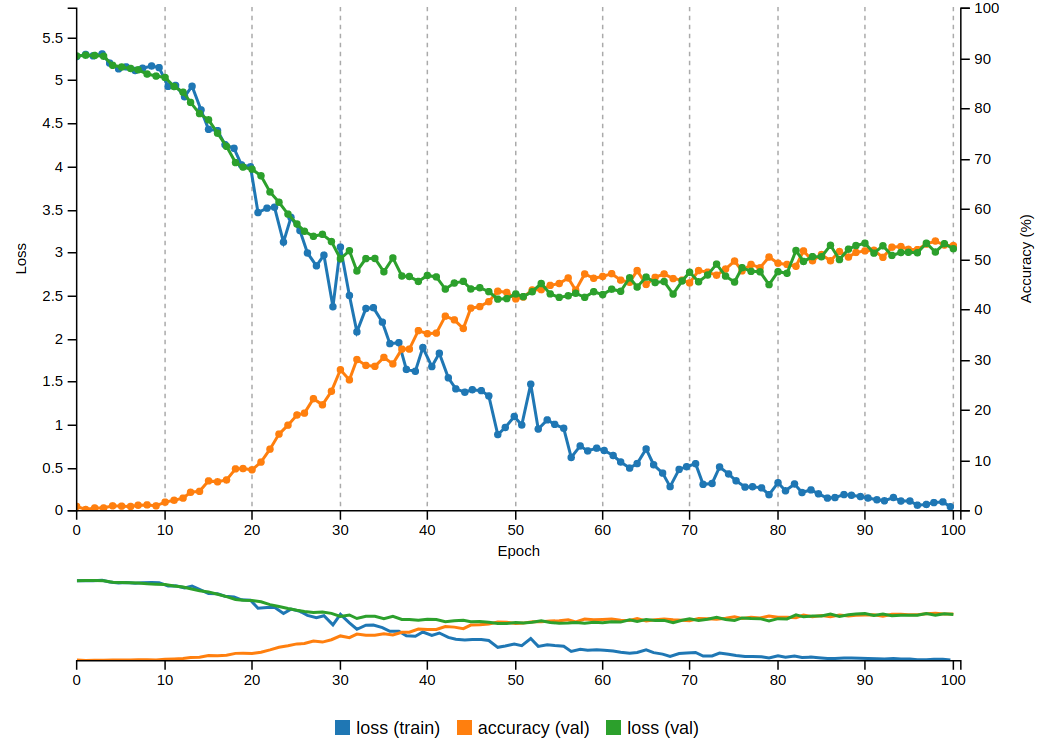
(image error) Size: 104 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 5
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,396 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 9
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 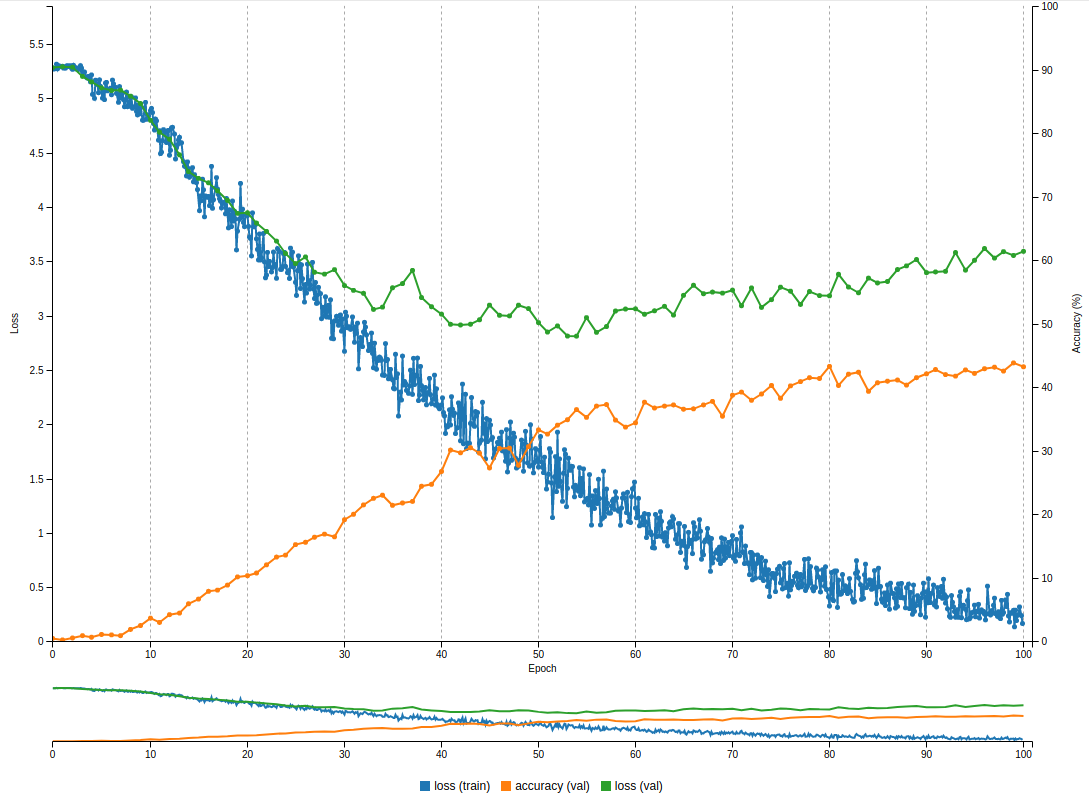
(image error) Size: 127 KiB |
@ -0,0 +1,443 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 9
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 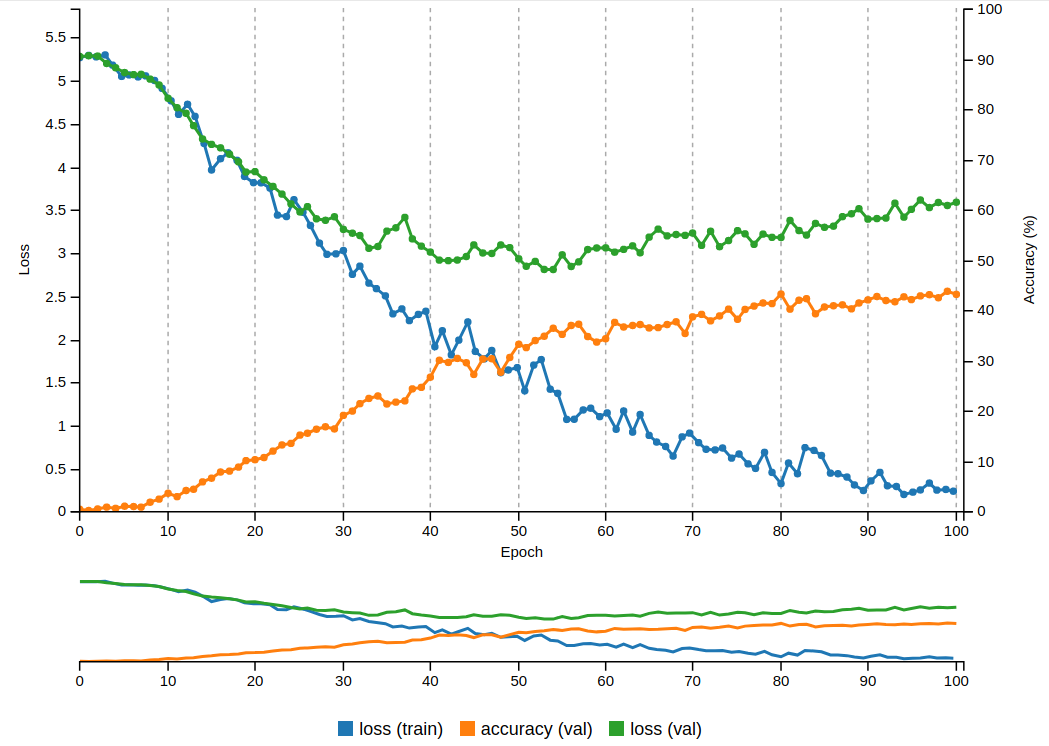
(image error) Size: 106 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.00999999977648
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.999801933765
|
||||
momentum: 0.899999976158
|
||||
weight_decay: 9.99999974738e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,437 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-MAN-3/digits/jobs/20210421-230320-902c/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1.5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv1.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 176
|
||||
kernel_size: 9
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv1.5"
|
||||
top: "conv1.5"
|
||||
}
|
||||
layer {
|
||||
name: "norm1.5"
|
||||
type: "LRN"
|
||||
bottom: "conv1.5"
|
||||
top: "norm1.5"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1.5"
|
||||
type: "Pooling"
|
||||
bottom: "norm1.5"
|
||||
top: "pool1.5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1.5"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.99999974738e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00499999988824
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.10000000149
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.00999999977648
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,466 @@
|
||||
# AlexNet
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
include { stage: "train" }
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
include { stage: "val" }
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 1
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 0.0001
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 2
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 0.0001
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 3
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 3.5
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 4
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
################
|
||||
# CONV 5
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# DENSE 1
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.005
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# DENSE 2
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.005
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# OUTPUT
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
# Since num_output is unset, DIGITS will automatically set it to the
|
||||
# number of classes in your dataset.
|
||||
# Uncomment this line to set it explicitly:
|
||||
#num_output: 1000
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.01
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
################
|
||||
# STATS
|
||||
################
|
||||
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include { stage: "val" }
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude { stage: "deploy" }
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include { stage: "deploy" }
|
||||
}
|
||||
@ -0,0 +1,374 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 192
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 118 KiB |
@ -0,0 +1,421 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 192
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 103 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.0099999998
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.99980193
|
||||
momentum: 0.89999998
|
||||
weight_decay: 9.9999997e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,415 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 192
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,374 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 576
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 116 KiB |
@ -0,0 +1,421 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 576
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
{kind=link}
|
After 
(image error) Size: 102 KiB |
@ -0,0 +1,14 @@
|
||||
test_iter: 51
|
||||
test_interval: 102
|
||||
base_lr: 0.0099999998
|
||||
display: 12
|
||||
max_iter: 10200
|
||||
lr_policy: "exp"
|
||||
gamma: 0.99980193
|
||||
momentum: 0.89999998
|
||||
weight_decay: 9.9999997e-05
|
||||
snapshot: 102
|
||||
snapshot_prefix: "snapshot"
|
||||
solver_mode: GPU
|
||||
net: "train_val.prototxt"
|
||||
solver_type: SGD
|
||||
@ -0,0 +1,415 @@
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TRAIN
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/train_db"
|
||||
batch_size: 128
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
mean_file: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/mean.binaryproto"
|
||||
}
|
||||
data_param {
|
||||
source: "/mnt/bigdisk/DIGITS-AMB-2/digits/jobs/20210419-113214-d311/val_db"
|
||||
batch_size: 32
|
||||
backend: LMDB
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 576
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
phase: TEST
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
}
|
||||
@ -0,0 +1,374 @@
|
||||
input: "data"
|
||||
input_shape {
|
||||
dim: 1
|
||||
dim: 3
|
||||
dim: 227
|
||||
dim: 227
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 196
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
}
|
||||
{kind=link}
|
After 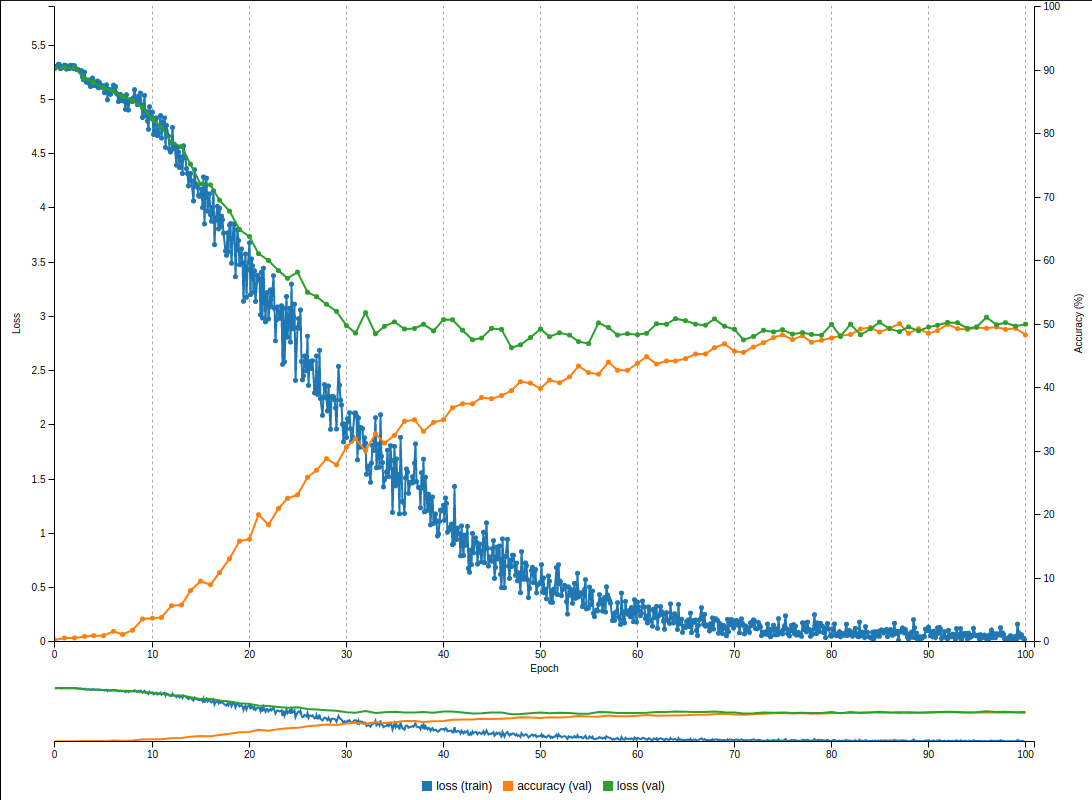
(image error) Size: 116 KiB |
@ -0,0 +1,421 @@
|
||||
name: "AlexNet"
|
||||
layer {
|
||||
name: "train-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "train"
|
||||
}
|
||||
transform_param {
|
||||
mirror: true
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 128
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "val-data"
|
||||
type: "Data"
|
||||
top: "data"
|
||||
top: "label"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
transform_param {
|
||||
crop_size: 227
|
||||
}
|
||||
data_param {
|
||||
batch_size: 32
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 96
|
||||
kernel_size: 11
|
||||
stride: 4
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu1"
|
||||
type: "ReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "norm1"
|
||||
type: "LRN"
|
||||
bottom: "conv1"
|
||||
top: "norm1"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "norm1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 2
|
||||
kernel_size: 5
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu2"
|
||||
type: "ReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "norm2"
|
||||
type: "LRN"
|
||||
bottom: "conv2"
|
||||
top: "norm2"
|
||||
lrn_param {
|
||||
local_size: 5
|
||||
alpha: 9.9999997e-05
|
||||
beta: 0.75
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "norm2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3"
|
||||
type: "ReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "conv3.5"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv3.5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu3.5"
|
||||
type: "ReLU"
|
||||
bottom: "conv3.5"
|
||||
top: "conv3.5"
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "conv3.5"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 384
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu4"
|
||||
type: "ReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "Convolution"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 256
|
||||
pad: 1
|
||||
kernel_size: 3
|
||||
group: 2
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu5"
|
||||
type: "ReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
layer {
|
||||
name: "pool5"
|
||||
type: "Pooling"
|
||||
bottom: "conv5"
|
||||
top: "pool5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc6"
|
||||
type: "InnerProduct"
|
||||
bottom: "pool5"
|
||||
top: "fc6"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu6"
|
||||
type: "ReLU"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
}
|
||||
layer {
|
||||
name: "drop6"
|
||||
type: "Dropout"
|
||||
bottom: "fc6"
|
||||
top: "fc6"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc7"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc6"
|
||||
top: "fc7"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4096
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0049999999
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.1
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "relu7"
|
||||
type: "ReLU"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
}
|
||||
layer {
|
||||
name: "drop7"
|
||||
type: "Dropout"
|
||||
bottom: "fc7"
|
||||
top: "fc7"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.5
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "fc8"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc7"
|
||||
top: "fc8"
|
||||
param {
|
||||
lr_mult: 1.0
|
||||
decay_mult: 1.0
|
||||
}
|
||||
param {
|
||||
lr_mult: 2.0
|
||||
decay_mult: 0.0
|
||||
}
|
||||
inner_product_param {
|
||||
weight_filler {
|
||||
type: "gaussian"
|
||||
std: 0.0099999998
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0.0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "accuracy"
|
||||
type: "Accuracy"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "accuracy"
|
||||
include {
|
||||
stage: "val"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "loss"
|
||||
type: "SoftmaxWithLoss"
|
||||
bottom: "fc8"
|
||||
bottom: "label"
|
||||
top: "loss"
|
||||
exclude {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "softmax"
|
||||
type: "Softmax"
|
||||
bottom: "fc8"
|
||||
top: "softmax"
|
||||
include {
|
||||
stage: "deploy"
|
||||
}
|
||||
}
|
||||