Affected files: .obsidian/graph.json .obsidian/workspace.json STEM/AI/Neural Networks/CNN/GAN/CycleGAN.md STEM/AI/Neural Networks/CNN/GAN/DC-GAN.md STEM/AI/Neural Networks/CNN/GAN/GAN.md STEM/AI/Neural Networks/CNN/GAN/StackGAN.md STEM/AI/Neural Networks/CNN/GAN/cGAN.md STEM/AI/Neural Networks/CV/Visual Search/Visual Search.md Tattoo/Artists.md Tattoo/Engineering.md Tattoo/Flowers.md Tattoo/Music.md Tattoo/Plans.md Tattoo/Sources.md |
||
|---|---|---|
| .. | ||
| FCN | ||
| GAN | ||
| CNN.md | ||
| Convolutional Layer.md | ||
| Examples.md | ||
| Inception Layer.md | ||
| Interpretation.md | ||
| Max Pooling.md | ||
| Normalisation.md | ||
| README.md | ||
| UpConv.md | ||
| tags | |
|---|---|
|
Before 2010s
- Data hungry
- Need lots of training data
- Processing power
- Niche
- No-one cared/knew about CNNs
After
- ImageNet
- 16m images, 1000 classes
- GPUs
- General processing GPUs
- CUDA
- NIPS/ECCV 2012
- Double digit % gain on ImageNet accuracy
Full Connected
- Move from convolutional operations towards vector output
- Stochastic drop-out
- Sub-sample channels and only connect some to dense layers
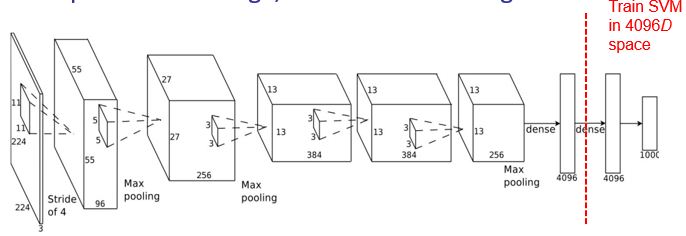
As a Descriptor
- Most powerful as a deeply learned feature extractor
- Dense classifier at the end isn't fantastic
- Use SVM to classify prior to penultimate layer #classification
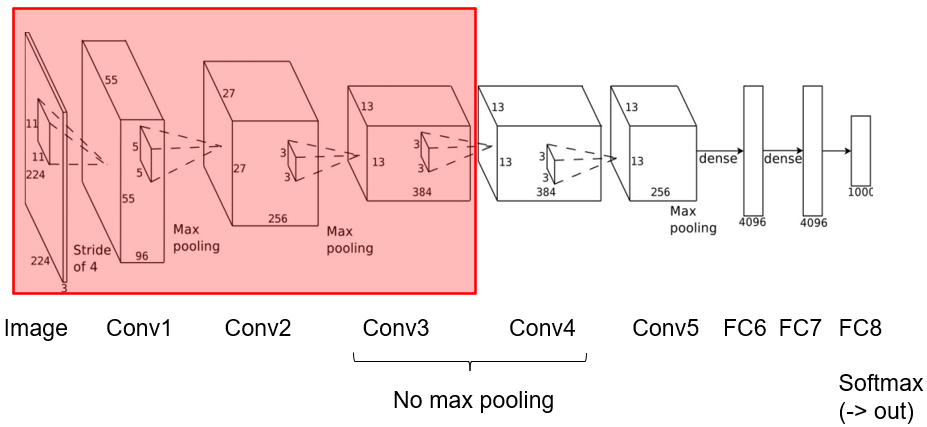
Finetuning
- Observations
- Most CNNs have similar weights in conv1
- Most useful CNNs have several conv layers
- Many weights
- Lots of training data
- Training data is hard to get
- Labelling
- Reuse weights from other network
- Freeze weights in first 3-5 conv layers
- Learning rate = 0
- Randomly initialise remaining layers
- Continue with existing weights
Training
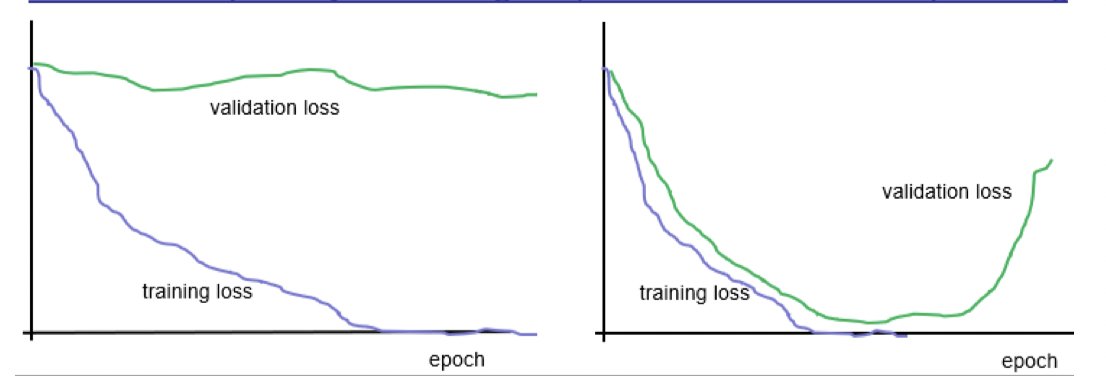
- Validation & training loss
- Early
- Under-fitting
- Training not representative
- Later
- Overfitting
- V.loss can help adjust learning rate
- Or indicate when to stop training