vault backup: 2023-06-07 09:02:27
Affected files: STEM/AI/Classification/Classification.md STEM/AI/Classification/Decision Trees.md STEM/AI/Classification/Gradient Boosting Machine.md STEM/AI/Classification/Logistic Regression.md STEM/AI/Classification/Random Forest.md STEM/AI/Classification/Supervised.md STEM/AI/Classification/Supervised/README.md STEM/AI/Classification/Supervised/SVM.md STEM/AI/Classification/Supervised/Supervised.md STEM/AI/Learning.md STEM/AI/Neural Networks/Learning/Boltzmann.md STEM/AI/Neural Networks/Learning/Competitive Learning.md STEM/AI/Neural Networks/Learning/Credit-Assignment Problem.md STEM/AI/Neural Networks/Learning/Hebbian.md STEM/AI/Neural Networks/Learning/Learning.md STEM/AI/Neural Networks/Learning/README.md STEM/AI/Neural Networks/RNN/Autoencoder.md STEM/AI/Neural Networks/RNN/Deep Image Prior.md STEM/AI/Neural Networks/RNN/MoCo.md STEM/AI/Neural Networks/RNN/Representation Learning.md STEM/AI/Neural Networks/RNN/SimCLR.md STEM/img/comp-learning.png STEM/img/competitive-geometric.png STEM/img/confusion-matrix.png STEM/img/decision-tree.png STEM/img/deep-image-prior-arch.png STEM/img/deep-image-prior-results.png STEM/img/hebb-learning.png STEM/img/moco.png STEM/img/receiver-operator-curve.png STEM/img/reinforcement-learning.png STEM/img/rnn+autoencoder-variational.png STEM/img/rnn+autoencoder.png STEM/img/simclr.png STEM/img/sup-representation-learning.png STEM/img/svm-c.png STEM/img/svm-non-linear-project.png STEM/img/svm-non-linear-separated.png STEM/img/svm-non-linear.png STEM/img/svm-optimal-plane.png STEM/img/svm.png STEM/img/unsup-representation-learning.png
@ -9,7 +9,7 @@
|
||||
Argument that gives the maximum value from a target function
|
||||
|
||||
# Gaussian Classifier
|
||||
[Training](Supervised.md)
|
||||
[Training](Supervised/Supervised.md)
|
||||
- Each class $i$ has it's own Gaussian $N_i=N(m_i,v_i)$
|
||||
|
||||
$$\hat i=\text{argmax}_i\left(p(o_t|N_i)\cdot P(N_i)\right)$$
|
||||
|
||||
4
AI/Classification/Decision Trees.md
Normal file
@ -0,0 +1,4 @@
|
||||
- Flowchart like design
|
||||
- Iterative decision making
|
||||
|
||||

|
||||
7
AI/Classification/Gradient Boosting Machine.md
Normal file
@ -0,0 +1,7 @@
|
||||
- Higher level take
|
||||
- Iteratively train more models addressing weak points
|
||||
- Well paired with decision trees
|
||||
- Strictly outperform random forest most of the time
|
||||
- Similar properties
|
||||
- One of the best algorithm for dealing with non perceptual data
|
||||
- XGBoost
|
||||
16
AI/Classification/Logistic Regression.md
Normal file
@ -0,0 +1,16 @@
|
||||
“hello world”
|
||||
Related to naïve bayes
|
||||
|
||||
- Statistical model
|
||||
- Uses ***logistic function*** to model a ***categorical*** dependent variable
|
||||
|
||||
# Types
|
||||
- Binary
|
||||
- 2 classes
|
||||
- Multinomial
|
||||
- Multiple classes without ordering
|
||||
- Categories
|
||||
- Ordinal
|
||||
- Multiple ordered classes
|
||||
- Star rating
|
||||
|
||||
1
AI/Classification/Random Forest.md
Normal file
@ -0,0 +1 @@
|
||||
“Almost always the second best algorithm for any shallow ML task”
|
||||
@ -1,5 +0,0 @@
|
||||
|
||||
# Gaussian Classifier
|
||||
- With $T$ labelled data
|
||||
|
||||
$$q_t(i)=$$
|
||||
1
AI/Classification/Supervised/README.md
Symbolic link
@ -0,0 +1 @@
|
||||
Supervised.md
|
||||
74
AI/Classification/Supervised/SVM.md
Normal file
@ -0,0 +1,74 @@
|
||||
[Towards Data Science: SVM](https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589)
|
||||
[Towards Data Science: SVM an overview](https://towardsdatascience.com/https-medium-com-pupalerushikesh-svm-f4b42800e989)
|
||||
|
||||
- Dividing line between two classes
|
||||
- Optimal hyperplane for a space
|
||||
- Margin maximising hyperplane
|
||||
- Can be used for
|
||||
- Classification
|
||||
- SVC
|
||||
- Regression
|
||||
- SVR
|
||||
- Alternative to Eigenmodels for supervised classification
|
||||
- For smaller datasets
|
||||
- Hard to scale on larger sets
|
||||
|
||||

|
||||
- Support vector points
|
||||
- Closest points to the hyperplane
|
||||
- Lines to hyperplane are support vectors
|
||||
|
||||
- Maximise margin between classes
|
||||
- Take dot product of test point with vector perpendicular to support vector
|
||||
- Sign determines class
|
||||
|
||||
# Pros
|
||||
- Linear or non-linear discrimination
|
||||
- Effective in higher dimensions
|
||||
- Effective when number of features higher than training examples
|
||||
- Best for when classes are separable
|
||||
- Outliers have less impact
|
||||
|
||||
# Cons
|
||||
- Long time for larger datasets
|
||||
- Doesn’t do well when overlapping
|
||||
- Selecting appropriate kernel
|
||||
|
||||
# Parameters
|
||||
- C
|
||||
- How smooth the decision boundary is
|
||||
- Larger C makes more curvy
|
||||
- 
|
||||
- Gamma
|
||||
- Controls area of influence for data points
|
||||
- High gamma reduces influence of faraway points
|
||||
|
||||
# Hyperplane
|
||||
|
||||
$$\beta_0+\beta_1X_1+\beta_2X_2+\cdot\cdot\cdot+\beta_pX_p=0$$
|
||||
- $p$-dimensional space
|
||||
- If $X$ satisfies equation
|
||||
- On plane
|
||||
- Maximal margin hyperplane
|
||||
- Perpendicular distance from each observation to given plane
|
||||
- Best plane has highest distance
|
||||
- If support vector points shift
|
||||
- Plane shifts
|
||||
- Hyperplane only depends on the support vectors
|
||||
- Rest don't matter
|
||||
|
||||

|
||||
|
||||
# Linearly Separable
|
||||
- Not linearly separable
|
||||

|
||||
- Add another dimension
|
||||
- $z=x^2+y^2$
|
||||
- Square of the distance of the point from the origin
|
||||

|
||||
- Now separable
|
||||
- Let $z=k$
|
||||
- $k$ is a constant
|
||||
- Project linear separator back to 2D
|
||||
- Get circle
|
||||

|
||||
23
AI/Classification/Supervised/Supervised.md
Normal file
@ -0,0 +1,23 @@
|
||||
|
||||
# Gaussian Classifier
|
||||
- With $T$ labelled data
|
||||
$$q_t(i)=
|
||||
\begin{cases}
|
||||
1 & \text{if class } i \\
|
||||
0 & \text{otherwise}
|
||||
\end{cases}$$
|
||||
- Indicator function
|
||||
|
||||
- Mean parameter
|
||||
$$\hat m_i=\frac{\sum_tq_t(i)o_t}{\sum_tq_t(i)}$$
|
||||
- Variance parameter
|
||||
$$\hat v_i=\frac{\sum_tq_t(i)(o_t-\hat m_i)^2}{\sum_tq_t(i)}$$
|
||||
|
||||
- Distribution weight
|
||||
- Class prior
|
||||
- $P(N_i)$
|
||||
$$\hat c_i=\frac 1 T \sum_tq_t(i)$$
|
||||
|
||||
$$\hat \mu_i=\frac{\sum_{t=1}^Tq_t(i)o_t}{\sum_{t=1}^Tq_t(i)}$$
|
||||
$$\hat\sum_i=\frac{\sum_{t=1}^Tq_t(i)(o_t-\mu_i)(o_t-\mu_i)^T}{\sum_{t=1}^Tq_t(i)}$$
|
||||
- For K-dimensional
|
||||
63
AI/Learning.md
Normal file
@ -0,0 +1,63 @@
|
||||
# Supervised
|
||||
- Dataset with inputs manually annotated for desired output
|
||||
- Desired output = supervisory signal
|
||||
- Manually annotated = ground truth
|
||||
- Annotated correct categories
|
||||
|
||||
## Split data
|
||||
- Training set
|
||||
- Test set
|
||||
***Don't test on training data***
|
||||
|
||||
## Top-K Accuracy
|
||||
- Whether correct answer appears in the top-k results
|
||||
|
||||
## Confusion Matrix
|
||||
Samples described by ***feature vector***
|
||||
Dataset forms a matrix
|
||||

|
||||
|
||||
# Un-Supervised
|
||||
- No example outputs given, learns how to categorise
|
||||
- No teacher or critic
|
||||
|
||||
## Harder
|
||||
- Must identify relevant distinguishing features
|
||||
- Must decide on number of categories
|
||||
|
||||
# Reinforcement Learning
|
||||
- No teacher - critic instead
|
||||
- Continued interaction with the environment
|
||||
- Minimise a scalar performance index
|
||||
|
||||

|
||||
|
||||
- Critic
|
||||
- Converts primary reinforcement to heuristic reinforcement
|
||||
- Both scalar inputs
|
||||
- Delayed reinforcement
|
||||
- System observes temporal sequence of stimuli
|
||||
- Results in generation of heuristic reinforcement signal
|
||||
- Minimise cost-to-go function
|
||||
- Expectation of cumulative cost of actions taken over sequence of steps
|
||||
- Instead of just immediate cost
|
||||
- Earlier actions may have been good
|
||||
- Identify and feedback to environment
|
||||
- Closely related to dynamic programming
|
||||
|
||||
## Difficulties
|
||||
- No teacher to provide desired response
|
||||
- Must solve temporal credit assignment problem
|
||||
- Need to know which actions were the good ones
|
||||
|
||||
# Fitting
|
||||
- Over-fitting
|
||||
- Classifier too specific to training set
|
||||
- Can't adequately generalise
|
||||
- Under-fitting
|
||||
- Too general, not inferred enough detail
|
||||
- Learns non-discriminative or non-desired pattern
|
||||
|
||||
# ROC
|
||||
Receiver Operator Characteristic Curve
|
||||

|
||||
30
AI/Neural Networks/Learning/Boltzmann.md
Normal file
@ -0,0 +1,30 @@
|
||||
- Stochastic
|
||||
- Recurrent structure
|
||||
- Binary operation (+/- 1)
|
||||
- Energy function
|
||||
|
||||
$$E=-\frac 1 2 \sum_j\sum_k w_{kj}x_kx_j$$
|
||||
- $j\neq k$
|
||||
- No self-feedback
|
||||
- $x$ = neuron state
|
||||
- Neurons randomly flip from $x$ to $-x$
|
||||
|
||||
$$P(x_k \rightarrow-x_k)=\frac 1 {1+e^{\frac{-\Delta E_k}{T}}}$$
|
||||
|
||||
- Energy change based on pseudo-temperature
|
||||
- System will reach thermal equilibrium
|
||||
- Delta E is the energy change resulting from the flip
|
||||
- Visible and hidden neurons
|
||||
- Visible act as interface between network and environment
|
||||
- Hidden always operate freely
|
||||
|
||||
# Operation Modes
|
||||
- Clamped
|
||||
- Visible neurons are clamped onto specific states determined by environment
|
||||
- Free-running
|
||||
- All neurons able to operate freely
|
||||
- $\rho_{kj}^+$ = Correlation between states while clamped
|
||||
- $\rho_{kj}^-$ = Correlation between states while free
|
||||
- Both exist between +/- 1
|
||||
|
||||
$$\Delta w_{kj}=\eta(\rho_{kj}^+-\rho_{kj}^-), \space j\neq k$$
|
||||
40
AI/Neural Networks/Learning/Competitive Learning.md
Normal file
@ -0,0 +1,40 @@
|
||||
- Only single output neuron fires
|
||||
|
||||
1. Set of homogeneous neurons with some randomly distributed synaptic weights
|
||||
- Respond differently to given set of input patterns
|
||||
2. Limit imposed on strength of each neuron
|
||||
3. Mechanism to allow neurons to compete for right to respond to a given subset of inputs
|
||||
- Only one output neuron active at a time
|
||||
- Or only one neuron per group
|
||||
- ***Winner-takes-all neuron***
|
||||
|
||||

|
||||
|
||||
- Lateral inhibition
|
||||
- Neurons inhibit other neurons
|
||||
- Winning neuron must have highest induced local field for given input pattern
|
||||
- Winning neuron is squashed to 1
|
||||
- Others are clamped to 0
|
||||
|
||||
$$y_k=
|
||||
\begin{cases}
|
||||
1 & \text{if } v_k > v_j \text{ for all } j,j\neq k \\
|
||||
0 & \text{otherwise}
|
||||
\end{cases}
|
||||
$$
|
||||
|
||||
- Neuron has fixed amount of weight spread amongst input synapses
|
||||
- Sums to 1
|
||||
- Learn by shifting weights from inactive to active input nodes
|
||||
- Each input node relinquishes some proportion of weight
|
||||
- Distributed amongst active nodes
|
||||
|
||||
$$\Delta w_{kj}=
|
||||
\begin{cases}
|
||||
\eta(x_j-w_{kj}) & \text{if neuron $k$ wins the competition}\\
|
||||
0 & \text{if neuron $k$ loses the competition}
|
||||
\end{cases}$$
|
||||
|
||||
- Individual neurons learn to specialise on ensembles of similar patterns
|
||||
- Feature detectors
|
||||

|
||||
17
AI/Neural Networks/Learning/Credit-Assignment Problem.md
Normal file
@ -0,0 +1,17 @@
|
||||
- Assigning credit/blame for outcomes to each internal decision
|
||||
- Loading Problem
|
||||
- Loading a training set into the free parameters
|
||||
- Important to any learning machine attempting to improve performance in situations involving temporally extended behaviour
|
||||
|
||||
Two Sub-problems:
|
||||
- ***Temporal*** credit-assignment problem
|
||||
- Assigning credit for **outcomes** to **actions**
|
||||
- Involves time when actions that deserve credit were taken
|
||||
- Relevant when many actions taken and want to know which one was responsible
|
||||
- ***Structural*** credit-assignment problem
|
||||
- Assigning credit for **actions** to **internal decisions**
|
||||
- Involves internal structures of actions generated by system
|
||||
- Relevant for identifying which component should have behaviour altered
|
||||
- By how much
|
||||
|
||||
- Important in MLPs when there are many hidden neurons
|
||||
55
AI/Neural Networks/Learning/Hebbian.md
Normal file
@ -0,0 +1,55 @@
|
||||
*Time-dependent, highly local, strongly interactive*
|
||||
|
||||
- Oldest learning algorithm
|
||||
- Increases synaptic efficiency as a function of the correlation between presynaptic and postsynaptic activities
|
||||
|
||||
1. If two neurons on either side of a synapse are activated simultaneously/synchronously, then the strength of that synapse is selectively increased
|
||||
2. If two neurons on either side of a synapse are activated asynchronously, then that synapse is selectively weakened or eliminated
|
||||
|
||||
- Hebbian synapse
|
||||
- Time-dependent
|
||||
- Depends on times of pre/post-synaptic signals
|
||||
- Local
|
||||
- Interactive
|
||||
- Depends on both sides of synapse
|
||||
- True interaction between pre/post-synaptic signals
|
||||
- Cannot make prediction from either one by itself
|
||||
- Conjunctional or correlational
|
||||
- Based on conjunction of pre/post-synaptic signals
|
||||
- Conjunctional synapse
|
||||
- Modification classifications
|
||||
- Hebbian
|
||||
- **Increases** strength with **positively** correlated pre/post-synaptic signals
|
||||
- **Decreases** strength with **negatively** correlated pre/post-synaptic signals
|
||||
- Anti-Hebbian
|
||||
- **Decreases** strength with **positively** correlated pre/post-synaptic signals
|
||||
- **Increases** strength with **negatively** correlated pre/post-synaptic signals
|
||||
- Still Hebbian in nature, not in function
|
||||
- Non-Hebbian
|
||||
- Doesn't involve above correlations/time dependence etc
|
||||
|
||||
# Mathematically
|
||||
$$\Delta w_{kj}(n)=F\left(y_k(n),x_j(n)\right)$$
|
||||
- Generally
|
||||
- All Hebbian
|
||||
|
||||

|
||||
|
||||
## Hebb's Hypothesis
|
||||
$$\Delta w_{kj}(n)=\eta y_k(n)x_j(n)$$
|
||||
- Activity product rule
|
||||
- Exponential growth until saturation
|
||||
- No information stored
|
||||
- Selectivity lost
|
||||
|
||||
## Covariance Hypothesis
|
||||
$$\Delta w_{kj}(n)=\eta(x_j-\bar x)(y_k-\bar y)$$
|
||||
- Characterised by perturbation from of pre/post-synaptic signals from their mean over a given time interval
|
||||
- Average $x$ and $y$ constitute thresholds
|
||||
- Intercept at y = y bar
|
||||
- Similar to learning in the hippocampus
|
||||
|
||||
*Allows:*
|
||||
1. Convergence to non-trivial state
|
||||
- When x = x bar or y = y bar
|
||||
2. Prediction of both synaptic potentiation and synaptic depression
|
||||
5
AI/Neural Networks/Learning/Learning.md
Normal file
@ -0,0 +1,5 @@
|
||||
*Learning is a process by which the free parameters of a neural network are adapted through a process of stimulation by the environment in which the network is embedded. The type of learning is determined by the manner in which the parameter changes take place*
|
||||
|
||||
1. The neural network is **stimulated** by an environment
|
||||
2. The network undergoes **changes in its free parameters** as a result of this stimulation
|
||||
3. The network **responds in a new way** to the environment as a result of the change in internal structure
|
||||
1
AI/Neural Networks/Learning/README.md
Symbolic link
@ -0,0 +1 @@
|
||||
Learning.md
|
||||
10
AI/Neural Networks/RNN/Autoencoder.md
Normal file
@ -0,0 +1,10 @@
|
||||
- Sequence of strokes for sketching
|
||||
- LSTM backbone
|
||||
|
||||

|
||||
|
||||
# Variational
|
||||
- Learn mean and covariance to drive encoder stage
|
||||
- Generate different outputs by sampling latent space
|
||||
|
||||

|
||||
8
AI/Neural Networks/RNN/Deep Image Prior.md
Normal file
@ -0,0 +1,8 @@
|
||||
- Overfitted to image
|
||||
- Learn weights necessary to reconstruct from white noise
|
||||
- Trained from scratch on single image
|
||||
- Encodes prior for natural images
|
||||
- De-noise images
|
||||
|
||||

|
||||

|
||||
13
AI/Neural Networks/RNN/MoCo.md
Normal file
@ -0,0 +1,13 @@
|
||||
- Similar to SimCLR
|
||||
- Rich set of negatives
|
||||
- Sampled from previous epochs in queue
|
||||
- Two function for pos/neg and anchor
|
||||
- Pos/neg are delayed anchor weights
|
||||
- Updated with momentum
|
||||
- Two delay mechanisms
|
||||
- Two encoder functions
|
||||
- Negative encoder queue
|
||||
|
||||

|
||||
|
||||
$$\theta_k\leftarrow m\theta_k+(1-m)\theta_q$$
|
||||
13
AI/Neural Networks/RNN/Representation Learning.md
Normal file
@ -0,0 +1,13 @@
|
||||
# Unsupervised
|
||||
|
||||
- Auto-encoder FCN
|
||||
- Learns bottleneck (latent) representation
|
||||
- Information rich
|
||||
- $f(.)$ is CNN encoding function
|
||||

|
||||
|
||||
# Supervised
|
||||
- Triplet loss
|
||||
- Providing positive and negative requires supervision
|
||||
- Two losses
|
||||

|
||||
10
AI/Neural Networks/RNN/SimCLR.md
Normal file
@ -0,0 +1,10 @@
|
||||
1. Data augmentation
|
||||
- Crop patches from images in batch
|
||||
- Add colour jitter
|
||||
2. Within batch sample positive and negative
|
||||
- Patches from same image are positive
|
||||
- All other negative
|
||||
3. MLP layer to compute loss instead of bottleneck embedding
|
||||
- Head network for function of bottleneck
|
||||
|
||||

|
||||
BIN
img/comp-learning.png
Normal file
|
After 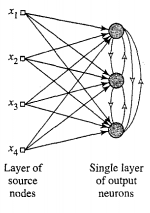
(image error) Size: 18 KiB |
BIN
img/competitive-geometric.png
Normal file
|
After 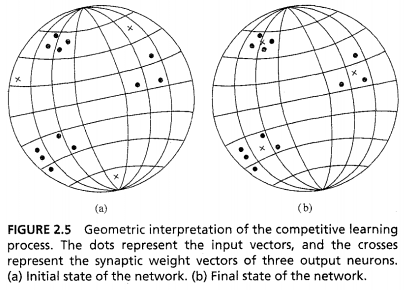
(image error) Size: 62 KiB |
BIN
img/confusion-matrix.png
Normal file
|
After 
(image error) Size: 311 KiB |
BIN
img/decision-tree.png
Normal file
|
After 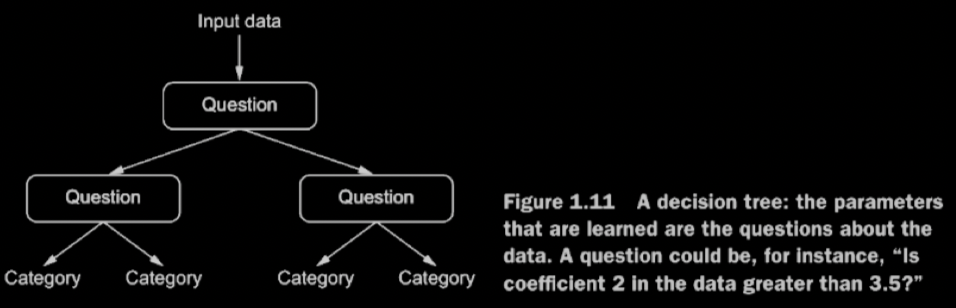
(image error) Size: 162 KiB |
BIN
img/deep-image-prior-arch.png
Normal file
|
After 
(image error) Size: 72 KiB |
BIN
img/deep-image-prior-results.png
Normal file
|
After 
(image error) Size: 496 KiB |
BIN
img/hebb-learning.png
Normal file
|
After 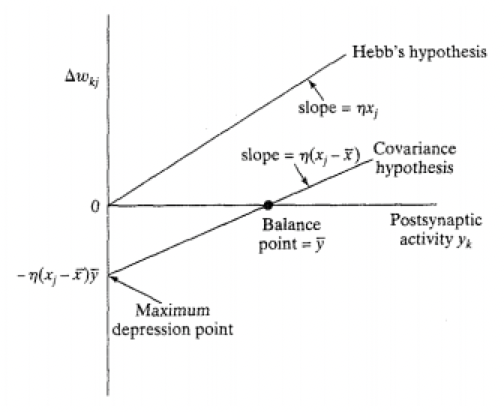
(image error) Size: 207 KiB |
BIN
img/moco.png
Normal file
|
After 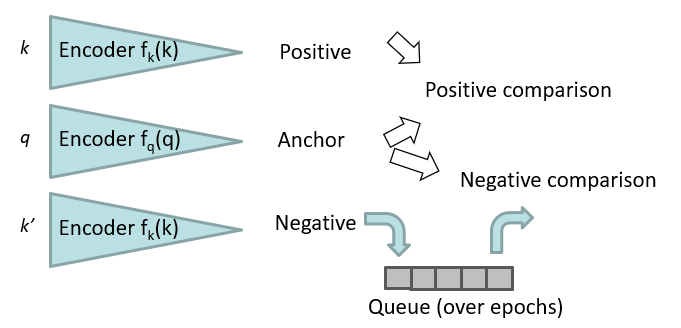
(image error) Size: 33 KiB |
BIN
img/receiver-operator-curve.png
Normal file
|
After 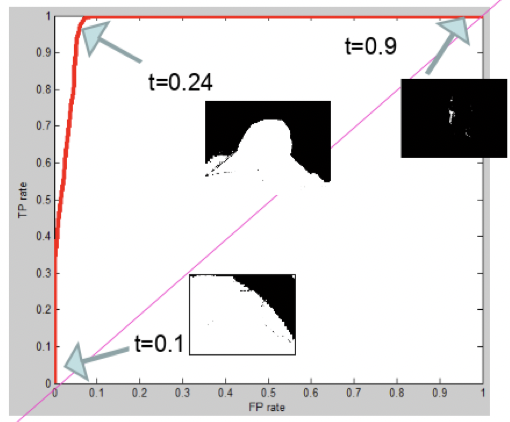
(image error) Size: 146 KiB |
BIN
img/reinforcement-learning.png
Normal file
|
After 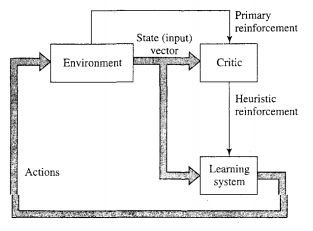
(image error) Size: 26 KiB |
BIN
img/rnn+autoencoder-variational.png
Normal file
|
After 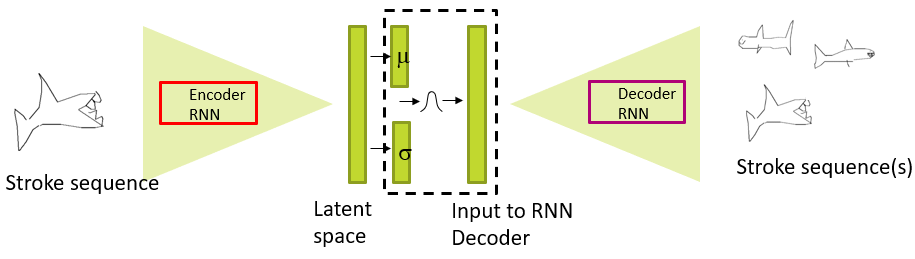
(image error) Size: 27 KiB |
BIN
img/rnn+autoencoder.png
Normal file
|
After 
(image error) Size: 21 KiB |
BIN
img/simclr.png
Normal file
|
After 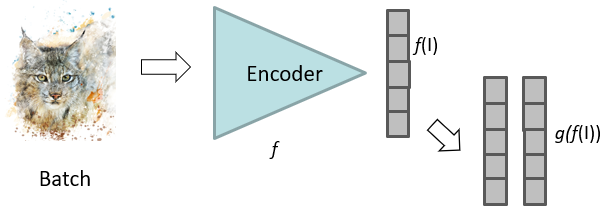
(image error) Size: 42 KiB |
BIN
img/sup-representation-learning.png
Normal file
|
After 
(image error) Size: 52 KiB |
BIN
img/svm-c.png
Normal file
|
After 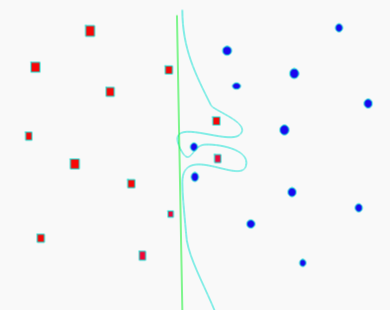
(image error) Size: 16 KiB |
BIN
img/svm-non-linear-project.png
Normal file
|
After 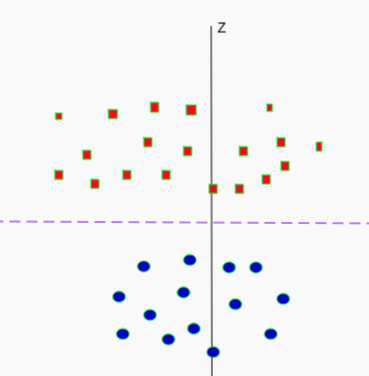
(image error) Size: 16 KiB |
BIN
img/svm-non-linear-separated.png
Normal file
|
After 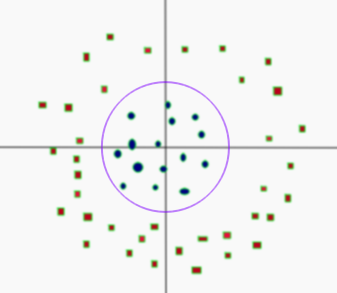
(image error) Size: 25 KiB |
BIN
img/svm-non-linear.png
Normal file
|
After 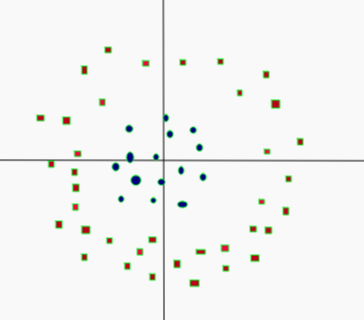
(image error) Size: 15 KiB |
BIN
img/svm-optimal-plane.png
Normal file
|
After 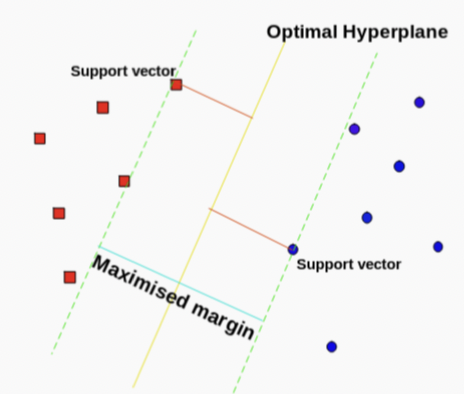
(image error) Size: 94 KiB |
BIN
img/svm.png
Normal file
|
After 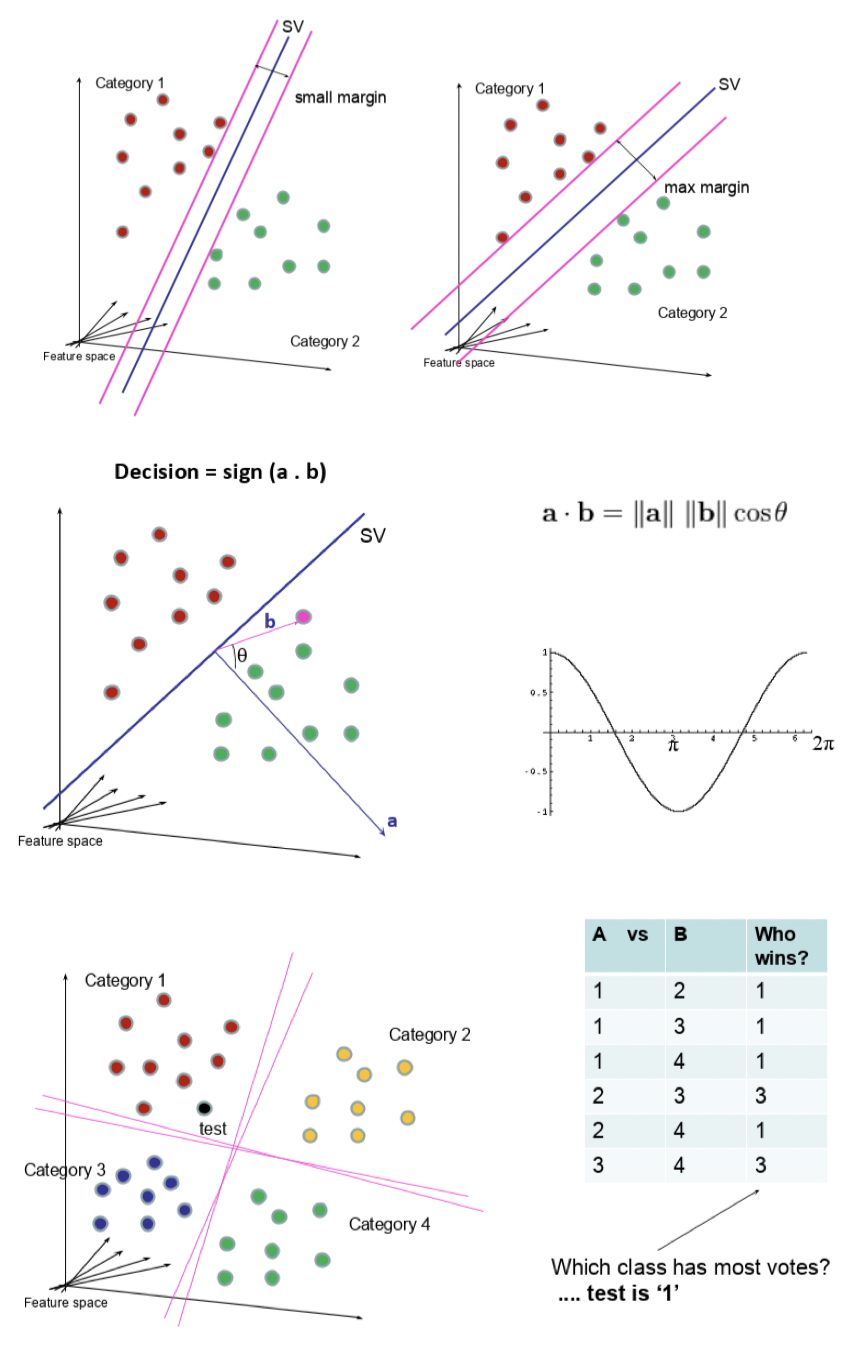
(image error) Size: 611 KiB |
BIN
img/unsup-representation-learning.png
Normal file
|
After 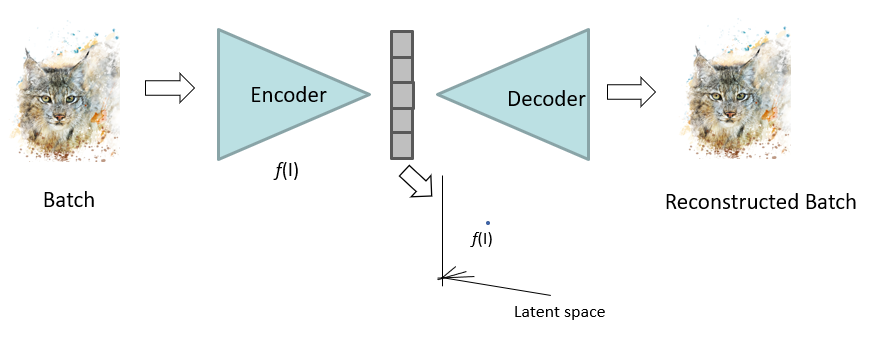
(image error) Size: 82 KiB |