began writing report, added nbconvert script
This commit is contained in:
parent
a28f36249f
commit
68760bde6b
1
.gitignore
vendored
1
.gitignore
vendored
@ -5,6 +5,7 @@ __pycache__/
|
||||
|
||||
*.pdf
|
||||
*~*
|
||||
*#*
|
||||
*.bak
|
||||
*.sav
|
||||
|
||||
|
||||
Binary file not shown.
|
Before 
(image error) Size: 471 KiB After 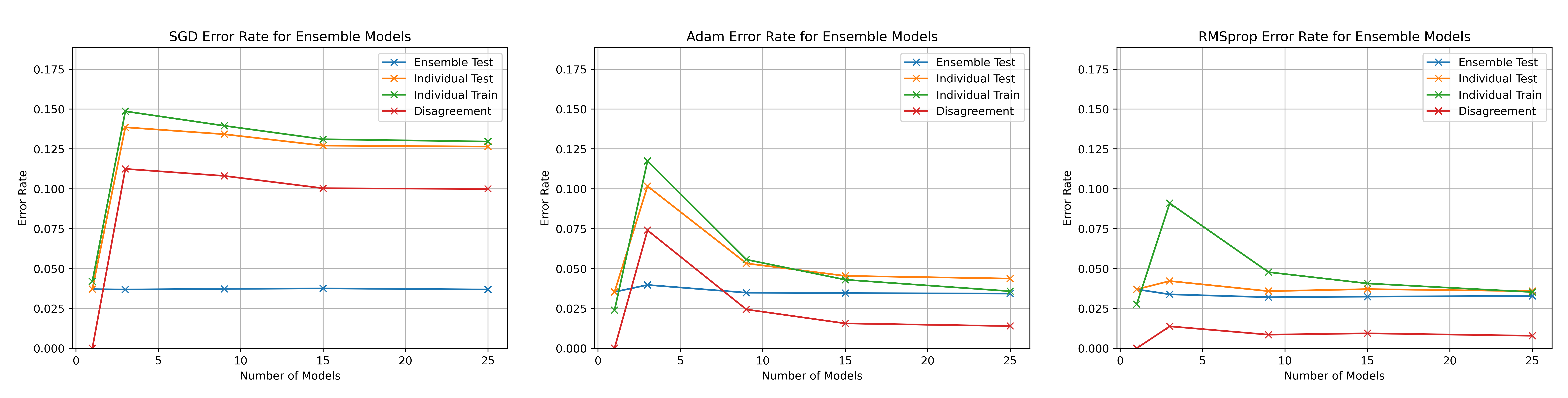
(image error) Size: 401 KiB
|
3
nbgen
Executable file
3
nbgen
Executable file
@ -0,0 +1,3 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
python -m jupyter nbconvert --to script nncw.ipynb
|
||||
@ -1,3 +1,54 @@
|
||||
% Encoding: UTF-8
|
||||
@comment{x-kbibtex-encoding=utf-8}
|
||||
|
||||
@comment{jabref-meta: databaseType:bibtex;}
|
||||
|
||||
@article{McCulloch1943,
|
||||
abstract = {Because of the “all-or-none” character of nervous activity, neural events and the relations among them can be treated by means of propositional logic. It is found that the behavior of every net can be described in these terms, with the addition of more complicated logical means for nets containing circles; and that for any logical expression satisfying certain conditions, one can find a net behaving in the fashion it describes. It is shown that many particular choices among possible neurophysiological assumptions are equivalent, in the sense that for every net behaving under one assumption, there exists another net which behaves under the other and gives the same results, although perhaps not in the same time. Various applications of the calculus are discussed.},
|
||||
author = {McCulloch, Warren S. and Pitts, Walter},
|
||||
doi = {10.1007/BF02478259},
|
||||
issn = {1522-9602},
|
||||
journal = {The bulletin of mathematical biophysics},
|
||||
number = {4},
|
||||
pages = {115–133},
|
||||
risfield_0_da = {1943/12/01},
|
||||
title = {A logical calculus of the ideas immanent in nervous activity},
|
||||
url = {https://link.springer.com/article/10.1007/BF02478259},
|
||||
urldate = {2021-04-06},
|
||||
volume = {5},
|
||||
year = {1943}
|
||||
}
|
||||
|
||||
@article{Rumelhart1986,
|
||||
abstract = {We describe a new learning procedure, back-propagation, for networks of neurone-like units. The procedure repeatedly adjusts the weights of the connections in the network so as to minimize a measure of the difference between the actual output vector of the net and the desired output vector. As a result of the weight adjustments, internal ‘hidden’ units which are not part of the input or output come to represent important features of the task domain, and the regularities in the task are captured by the interactions of these units. The ability to create useful new features distinguishes back-propagation from earlier, simpler methods such as the perceptron-convergence procedure1.},
|
||||
author = {Rumelhart, David E. and Hinton, Geoffrey E. and Williams, Ronald J.},
|
||||
doi = {10.1038/323533a0},
|
||||
issn = {1476-4687},
|
||||
journal = {Nature},
|
||||
number = {6088},
|
||||
pages = {533–536},
|
||||
risfield_0_da = {1986/10/01},
|
||||
title = {Learning representations by back-propagating errors},
|
||||
url = {https://www.nature.com/articles/323533a0},
|
||||
urldate = {2021-04-06},
|
||||
volume = {323},
|
||||
year = {1986}
|
||||
}
|
||||
|
||||
@misc{matlab-dataset,
|
||||
author = {MathWorks},
|
||||
title = {Sample Data Sets for Shallow Neural Networks},
|
||||
url = {https://es.mathworks.com/help/deeplearning/gs/sample-data-sets-for-shallow-neural-networks.html},
|
||||
urldate = {2021-04-06}
|
||||
}
|
||||
|
||||
@article{alexnet,
|
||||
author = {Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E},
|
||||
journaltitle = {Advances in neural information processing systems},
|
||||
pages = {1097–1105},
|
||||
title = {ImageNet Classification with Deep Convolutional Networks},
|
||||
url = {https://kr.nvidia.com/content/tesla/pdf/machine-learning/imagenet-classification-with-deep-convolutional-nn.pdf},
|
||||
urldate = {2021-04-05},
|
||||
volume = {25},
|
||||
year = {2012}
|
||||
}
|
||||
|
||||
@Comment{jabref-meta: databaseType:bibtex;}
|
||||
|
||||
@ -24,7 +24,7 @@ minimalistic
|
||||
todonotes
|
||||
\end_modules
|
||||
\maintain_unincluded_children false
|
||||
\language english
|
||||
\language british
|
||||
\language_package default
|
||||
\inputencoding utf8
|
||||
\fontencoding global
|
||||
@ -100,7 +100,7 @@ todonotes
|
||||
\defskip medskip
|
||||
\is_math_indent 0
|
||||
\math_numbering_side default
|
||||
\quotes_style english
|
||||
\quotes_style british
|
||||
\dynamic_quotes 0
|
||||
\papercolumns 1
|
||||
\papersides 1
|
||||
@ -293,16 +293,221 @@ setcounter{page}{1}
|
||||
Introduction
|
||||
\end_layout
|
||||
|
||||
\begin_layout Standard
|
||||
Artificial neural networks have been the object of research and investigation
|
||||
since the 1940s with
|
||||
\noun on
|
||||
McCulloch
|
||||
\noun default
|
||||
and
|
||||
\noun on
|
||||
Pitts
|
||||
\noun default
|
||||
' model of the artificial neuron
|
||||
\begin_inset CommandInset citation
|
||||
LatexCommand cite
|
||||
key "McCulloch1943"
|
||||
literal "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
or
|
||||
\emph on
|
||||
Threshold Logic Unit
|
||||
\emph default
|
||||
.
|
||||
Throughout the century, the development of the single and multi-layer perceptro
|
||||
ns (SLP/MLP) alongside the backpropagation algorithm
|
||||
\begin_inset CommandInset citation
|
||||
LatexCommand cite
|
||||
key "Rumelhart1986"
|
||||
literal "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
advanced the study of artificial intelligence.
|
||||
Throughout the 2010s, convolutional neural networks have proved critical
|
||||
in the field of computer vision and image recognition
|
||||
\begin_inset CommandInset citation
|
||||
LatexCommand cite
|
||||
key "alexnet"
|
||||
literal "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
.
|
||||
\end_layout
|
||||
|
||||
\begin_layout Standard
|
||||
This work investigates the ability of a shallow multi-layer perceptron to
|
||||
classify breast tumours as either benign or malignant.
|
||||
The architecture and parameters were varied before exploring how in order
|
||||
to evaluate how this affects performance.
|
||||
|
||||
\end_layout
|
||||
|
||||
\begin_layout Standard
|
||||
Investigations were carried out in
|
||||
\noun on
|
||||
Python
|
||||
\noun default
|
||||
using the
|
||||
\noun on
|
||||
TensorFlow
|
||||
\noun default
|
||||
package to construct, train and evaluate neural networks.
|
||||
The networks were trained using a supervised learning curriculum of labelled
|
||||
data taken from a standard
|
||||
\noun on
|
||||
MatLab
|
||||
\noun default
|
||||
dataset
|
||||
\begin_inset CommandInset citation
|
||||
LatexCommand cite
|
||||
key "matlab-dataset"
|
||||
literal "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
from the
|
||||
\noun on
|
||||
Deep Learning Toolbox
|
||||
\noun default
|
||||
.
|
||||
\end_layout
|
||||
|
||||
\begin_layout Standard
|
||||
Section
|
||||
\begin_inset CommandInset ref
|
||||
LatexCommand ref
|
||||
reference "sec:exp1"
|
||||
plural "false"
|
||||
caps "false"
|
||||
noprefix "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
investigates the effect of varying the number of hidden nodes on test accuracy
|
||||
along with the number of epochs that the MLPs are trained for.
|
||||
Section
|
||||
\begin_inset CommandInset ref
|
||||
LatexCommand ref
|
||||
reference "sec:exp2"
|
||||
plural "false"
|
||||
caps "false"
|
||||
noprefix "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
builds on the previous experiment by using reasonable parameter values
|
||||
to investigate performance when using an ensemble of models to classify
|
||||
in conjunction.
|
||||
The effect of varying the number of nodes and epochs throughout the ensemble
|
||||
was considered in order to determine whether combining multiple models
|
||||
could produce a better accuracy than those individually.
|
||||
Section
|
||||
\begin_inset CommandInset ref
|
||||
LatexCommand ref
|
||||
reference "sec:exp3"
|
||||
plural "false"
|
||||
caps "false"
|
||||
noprefix "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
investigates the effect of altering how the networks learn by changing
|
||||
the optimisation algorithm.
|
||||
Two additional algorithms to the previously used are considered and compared
|
||||
using the same test apparatus of section
|
||||
\begin_inset CommandInset ref
|
||||
LatexCommand ref
|
||||
reference "sec:exp2"
|
||||
plural "false"
|
||||
caps "false"
|
||||
noprefix "false"
|
||||
|
||||
\end_inset
|
||||
|
||||
.
|
||||
\end_layout
|
||||
|
||||
\begin_layout Section
|
||||
Hidden Nodes & Epochs (Exp 1)
|
||||
\begin_inset CommandInset label
|
||||
LatexCommand label
|
||||
name "sec:exp1"
|
||||
|
||||
\end_inset
|
||||
|
||||
|
||||
\end_layout
|
||||
|
||||
\begin_layout Standard
|
||||
This section investigates the effect of varying the number of hidden nodes
|
||||
in a single hidden layer of a multi-layer perceptron.
|
||||
This is compared to the effect of varying
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Results
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Discussion
|
||||
\end_layout
|
||||
|
||||
\begin_layout Section
|
||||
Ensemble Classification (Exp 2)
|
||||
\begin_inset CommandInset label
|
||||
LatexCommand label
|
||||
name "sec:exp2"
|
||||
|
||||
\end_inset
|
||||
|
||||
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Results
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Discussion
|
||||
\end_layout
|
||||
|
||||
\begin_layout Section
|
||||
Optimiser Comparisons (Exp 3)
|
||||
\begin_inset CommandInset label
|
||||
LatexCommand label
|
||||
name "sec:exp3"
|
||||
|
||||
\end_inset
|
||||
|
||||
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Optimisers
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsubsection
|
||||
Stochastic Gradient Descent
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsubsection
|
||||
RMSprop
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsubsection
|
||||
Adam
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Results
|
||||
\end_layout
|
||||
|
||||
\begin_layout Subsection
|
||||
Discussion
|
||||
\end_layout
|
||||
|
||||
\begin_layout Section
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user